Das erfolgreiche Data-Science-Projekt: Wie funktioniert es?
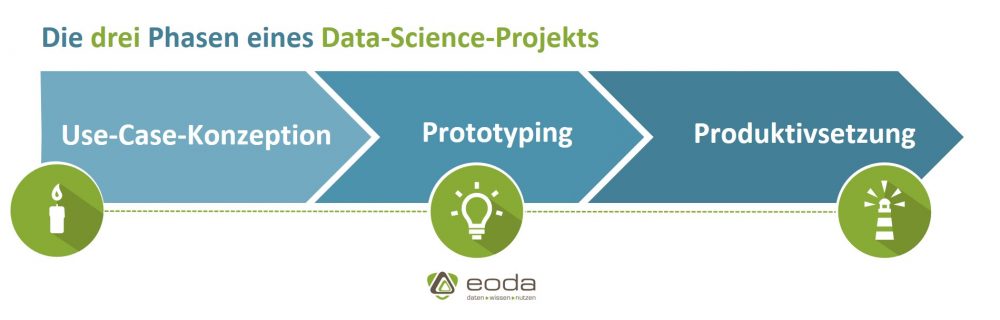
Data Science birgt ein enormes Potenzial für Unternehmen, doch die Hürde zum ersten Data-Science-Projekt scheint hoch: Zu schwammig sind die einzelnen Schritte, zu undurchschaubar wirkt der Aufwand. Wie ist der Ablauf eines typischen Data-Science-Projekts? Was ist bei der Durchführung wichtig? Und wie arbeitet der Data Scientist eigentlich genau? Wir lichten das Dunkel und geben Antworten.
Dabei ist es zweitrangig, ob das Projekt firmenintern, also mit einer eigenen Data-Science-Abteilung realisiert wird, oder ein externer Data-Science-Dienstleister beauftragt wurde – ein Projekt folgt grundsätzlich einem ähnlichen Verlauf. Wichtig dabei: eine gute Idee.
Erst die Arbeit, dann das Vergnügen – bei einem Data-Science-Projekt sind diese Schritte vertauscht. Der erste Schritt ist der aufregendste, denn jedes Data-Science-Projekt beginnt mit einer Vision und ist von einer Idee geleitet: Welchen Wert haben meine Daten? Welche Fragen können sie mir beantworten?
Whitepaper: Wie erschließe ich das Potenzial meiner Daten?
Erfahren Sie noch mehr zum Thema: Kompetenzen, Strukturen und Abläufe für erfolgreicher Data-Science-Projekte. Wir zeigen Ihnen den Weg von der Idee bis zur erfolgreichen Implementierung des Analysemodells in die Geschäftsprozesse.

Wanted: Der richtige Use Case
Wenn sich Unternehmen gleichzeitig kreativ, ohne Tellerränder und mit einer realistischen Erwartungshaltung an diese Fragen wagen, stehen die Chancen gut, ein von Erfolg geprägtes Data-Science-Projekt zu starten. Das Resultat dieses ersten Schrittes ist im besten Fall eine klar definierte Fragestellung oder Zielsetzung – keineswegs eine einfache Aufgabe.
Ein Beispiel: Stellen wir uns ein Unternehmen vor, dass bereit ist, die ersten digitalen Schritte mit einem Analytik-Projekt zu gehen, aber firmenintern kein Know-how zum Thema Datenanalyse vorweisen kann. Die einzelnen Fachabteilungen beschließen für das Projekt Ziele, ohne einen Experten zum Thema Datenanalyse einbezogen zu haben – hier besteht ein hohes Risiko, dass die Ziele unrealistisch sind oder sich eine Umsetzung aufgrund der falsch eingeschätzten Datenlage schwierig gestaltet. Besser: Data Science, Fachabteilung und (wenn nötig) zusätzliche Experten entwickeln gemeinsam eine Idee zum konkreten Use Case weiter, bei dem bereits mögliche Datenquellen, Zielgruppen und Potenziale berücksichtigt werden. Der Data Scientist startet auf dieser Grundlage den Analyseprozess.
Steht das Ziel, beginnt der Analyseprozess
Dieser ist vielschichtig und keineswegs linear, vielmehr gleicht er reiner Detektivarbeit. Bevor die eigentliche Analyse beginnt, geht der Data Scientist auf Spurensuche: Er will das Problem verstehen, das Business der Firma kennenlernen und den Use Case prüfen.
Üblicherweise bekommt er zu Beginn dieses Schrittes auch Zugang zu den Daten und identifiziert die relevanten Informationen für die Fragestellung. Dies setzt eine durchdachte Infrastruktur voraus: Cloudlösungen, VPN-Zugänge oder Festplatten auf der Datenseite und abhängig von der Datenmenge und der angestrebten Modell-Lösung eine geeignete Rechenkapazität. Ein Neuronales Netz braucht andere Kapazitäten als eine Lineare Regression – dies gilt es im Setup der Infrastruktur zu berücksichtigen, um unnötige Ressourcenengpässe während der Projektlaufzeit zu vermeiden. Nicht immer kann das Team die passenden Algorithmen und Methoden bereits jetzt identifizieren, eine gewisse Flexibilität ist daher immer Teil der Gestaltungsgrundlage eines Data-Science-Projekts – nicht umsonst sind (unsere) Data Scientists Fans von agilen Projektmanagement-Methoden.
Daten unter der Lupe
Der Datensatz ist die Basis einer jeden Analyse, hiermit steht und fällt der zuvor erdachte Use Case: „Unternehmen haben in der Regel mehr Daten als notwendig. Manchmal fehlen aber leider genau die Daten, die für die Analyse relevant wären“, weiß eoda Data Scientist Martin Schneider.
Bevor also die Analysestrategie konzipiert wird, schaut der Data Scientist genauer hin: Er prüft, ob der Datensatz die relevanten Daten enthält oder ob es sich lohnt, den Datensatz durch firmenexterne Datenquellen zu ergänzen. Spätestens jetzt ist auch der Data Scientist (ob extern oder intern) ein Experte für die vorliegenden Daten und entwickelt eine passgenaue Analysestrategie
Mit dem richtigen Algorithmus zum Modell
Ein gutes Data-Science-Projekt ist an dieser Stelle hoch iterativ, denn nicht zwingend führt der angedachte Algorithmus gleich beim ersten Versuch zum Erfolg. Es beginnt ein spannender Prozess mit dem Ziel, die beste Lösung für die Fragestellung zu finden. Dieser Workflow will gut vorbereitet sein und beginnt im Data Management: Die Datensätze werden auf den Prüfstand gestellt und die Werte (je nach Bedarf) rekodiert, aggregiert und fehlende Werte imputiert.
Auch wenn die beiden Begriffe häufig synonym verwendet werden, gibt es einen Unterschied: Das Modell ist der jeweilige Algorithmus, gefüttert mit den individuellen Projektdaten. Der Algorithmus ist das Instrument, um ein Modell zu kreieren.
Die perfekte Rezeptur für ein Data-Science-Projekt
Bevor die anschließende Modellbildung beginnt und der Algorithmus gefüttert wird, werden im Feature Engineering die Daten für den jeweiligen Algorithmus in Form gebracht. Vergleichbar mit einem Rezept benötigt ein jeder Algorithmus bestimmte Zutaten, damit die Zubereitung gelingt.
Bleiben wir in der Küche: Um das Ergebnis zu optimieren, wird auch hier immer wieder an den Zutaten und Komponenten (Parametern) geschraubt, bis das Ergebnis stimmt. Und wenn das Gericht (der Algorithmus) gar nicht schmeckt, muss eben etwas Neues her. Hier gilt wieder: Kreativität und Flexibilität sind essentielle Faktoren, um auch das letzte Potenzial aus dem Data-Science-Projekt zu schöpfen. Dabei ist Teamkompetenz gefragt, denn im Austausch mit dem Projektteam finden sich wichtige Informationen.
Das Projekt nähert sich hier seinem Abschluss. Wenn alle Beteiligten mit der Modellgüte zufrieden sind, wird das Data-Science-Projekt mit der gewünschten Dokumentation (beispielsweise einer kommentierten Übergabe des Codes) abgeschlossen und produktiv eingesetzt. Hier kommt möglicherweise auch der Data Engineer zum Einsatz und setzt die technischen Anforderungen an die Datenbank-Infrastruktur um. Zeit für den nächsten Use Case: Ein neues Data-Science-Projekt beginnt.
Wir realisieren Ihr Data-Science-Projekt
Als Data Science Experten sind wir von eoda Ihr Ansprechpartner, wenn es darum geht in einem Data-Science-Projekt Mehrwerte aus Daten zu generieren. Wir begleiten Sie von der Identifikation des richtigen Anwendungsfalls, über das Datenmanagement und die Modellbildung bis zur Implementierung des Analysemodells in Ihre Geschäftsprozesse.
Sie wollen Ihr Data-Science-Projekt in Eigenregie zum Erfolg führen? Sehr gerne stehen wir Ihnen auch mit Beratung und Code-Reviews zur Seite, um Sie dabei zu unterstützen, aus Ihrer Initiative einen Erfolg zu machen.
Erfahren Sie mehr darüber, wie wir von eoda Sie bei Ihren Analyseprojekten unterstützen können.