Mit Augmented Intelligence zu besseren Analyseergebnissen
Kassel, den 16. Januar 2020
Das Kasseler Data-Science-Unternehmen eoda GmbH erweitert seine Data-Science-Plattform YUNA um ein innovatives Feature: Mit dem Result Rating ist es möglich Ergebnisse von Datenanalysen noch schneller auf Plausibilität zu überprüfen. Auf diese Weise können ebenfalls Trainings-Datensätze entstehen, die Advanced Analytics und Machine Learning überhaupt erst ermöglichen.
Die Grundidee ist aus dem Internet bekannt: Mittels Google LLCs Captcha-Dienst muss vorgewiesen werden, dass ein Mensch und keine Software eine bestimmte Handlung durchführt. Was viele nicht wissen – Google nutzt diese Informationen, um die eigenen Algorithmen zur Bilderkennung zu verbessern.
Damit Datenanalysen verlässliche Ergebnisse liefern, müssen die zugrunde liegenden Algorithmen zunächst „trainiert“ werden. In YUNA funktioniert dies ähnlich wie beim genannten Captcha-Dienst: Die ausgegebenen Ergebnisse der Analyseskripte werden von Nutzern auf Plausibilität geprüft. Dies geschieht direkt in der Data-Science-Plattform, je nach gewählter Visualisierung. Mittels eines einfachen Tastendrucks wird das Ergebnis bestätigt oder abgelehnt. Diese Informationen werden über YUNA direkt an die Data Scientists zurückgespielt. Diese können mit dem Feedback ihre Algorithmen trainieren und anschließend über Skripte produktiv schalten. Oft fehlt es aber in Unternehmen an einem grundlegendem Datensatz, von dem man sicher weiß, dass Probleme bzw. die gewünschten Ergebnisse vorliegen. Dies kann über das Feature ebenso erstellt werden, wie die anschließende Bewertung der Ergebnisse.
„Das Feature kombiniert zwei essenzielle Faktoren: Das Schaffen einer Basis, auf der wir Data Scientists unsere Algorithmen trainieren können und das komfortable Bewerten der Ergebnisse danach – und das alles in einem Rutsch.“,
sagt Andreas Prawitt, Senior Data Scientist bei eoda GmbH.
Die Prüfung von Analyseergebnissen ist grundlegend
Das Prüfen und Bewerten und Analysenergebnissen an sich ist oft mühsam und langwierig. Die ausgespielten Ergebnisse werden, je nach Art, in verschiedenen Formaten oder einzelnen dedizierten Dateien abgelegt. Diese gilt es Stück für Stück zu sichten und zu prüfen. Die Ergebnisse werden dann an Data Scientists über verschiedene Kanäle rückgespielt und als Basis der nächsten Iteration des Analyseskriptes genutzt. Oft sind mehrere Anpassungsschleifen nötig. Dabei sind nicht nur verschiedene Personen, sondern auch verschiedene Anwendungen, Abteilungen sowie Kommunikationswege beteiligt – das Potenzial für Übertragungsfehler steigt mit jedem Medienbruch an.
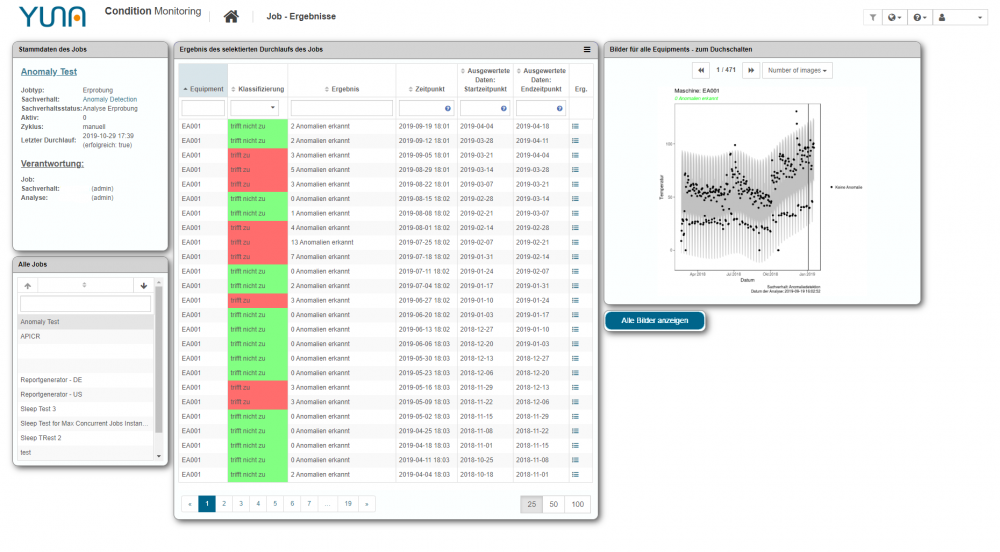
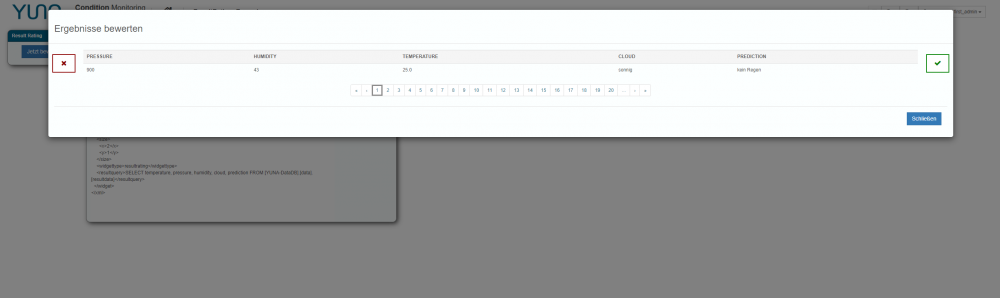
Data Scientists müssen mit YUNA also nicht mehr ihre Anwendungen verlassen. Die gesamte Analyse kann von der Konzeption, über die Evaluierung bis hin zur Produktivsetzung in einer einzigen Plattform geschehen. Im Vergleich zu bisherigen Verfahren ist dies nicht nur schneller, sondern insgesamt verständlicher, in der Nutzung deutlich unkomplizierter und sicherer gegenüber Fehlern. Dadurch wird nicht nur die Ergebnisqualität von Datenanalysen immens verbessert, sondern Machine-Learning-Algorithmen könnten gleichzeitig so gut trainiert werden, dass perspektivisch keine abschließende Verifikation durch Anwender geschehen muss. An diesen Punkten setzt das Result Rating in YUNA an und adressiert damit gleich vier fundamentale Hemmnisse: Die Schaffung eines grundlegenden Basis-Datensatzes, die eigentliche Bewertung, das Rückspielen der Ergebnisse und die damit verbundene und verkürzte Zeit zum Anpassen der Analyseskripte.