Kubernetes: Horizontale Skalierung von Data-Science-Anwendungen in der Cloud
Vorhersagemodelle, Machine-Learning-Algorithmen und Skripte zur Datenhaltung: Die moderne Data-Science-Anwendung weist nicht nur zunehmend mehr Komplexität auf, sondern stellt auch immer mehr die bestehende Infrastruktur durch temporäre Ressourcenpeaks auf die Probe. In diesem Artikel wollen wir darstellen, wie man mit Tools, wie zum Beispiel dem RStudio Job-Launcher in Verbindung mit einem Kubernetes-Cluster, die Ausführung von beliebigen Analyseskripten in die Cloud auslagern, skalieren und in die lokale Infrastruktur zurückspielen kann.
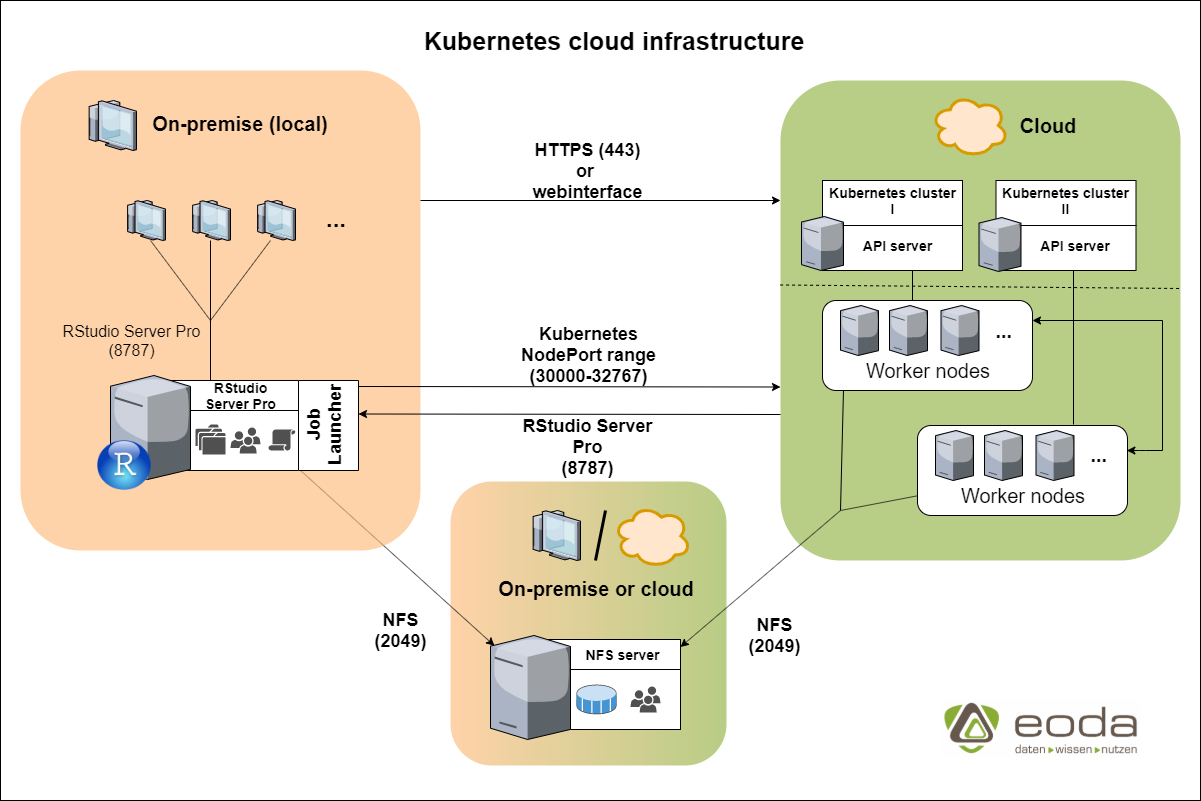
Eine kurze Einführung in Kubernetes und den Job-Launcher
Kubernetes wurde 2014 von Google entworfen und ist ein Open-Source publiziertes Container-Orchestrierungs-System. Im Fokus stehen bei diesen Systemen die automatisierte Bereitstellung, Skalierung und Verwaltung von Containeranwendungen. Ein Kubernetes-Cluster stellt dabei sogenannte (Worker) Nodes zur Verfügung, die von anderen Applikationen angesprochen werden können. Innerhalb der Nodes werden die nötigen Container dann in Pods hochgefahren und bereitgestellt. Besonders interessant ist in einem Statistik-/Analysekontext die Auslagerung oder horizontale Skalierbarkeit von rechenintensiven Analysen. Somit kann in einer Multi-User-Umgebung durch die Verteilung der Jobs auf die Worker Nodes sichergestellt werden, dass je nach Auslastung die exakt benötigte Menge an Ressourcen zur Verfügung gestellt wird. Im Analysekontext mit R kann hier der RStudio Job-Launcher, das unabhängige Tool von RStudio Server, seine Stärken ausspielen und Sessions sowie Skripte via Plugin direkt an ein Kubernetes-Cluster senden.
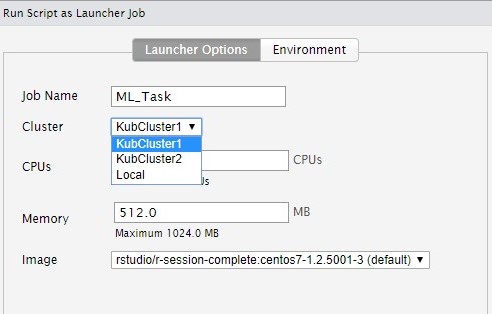
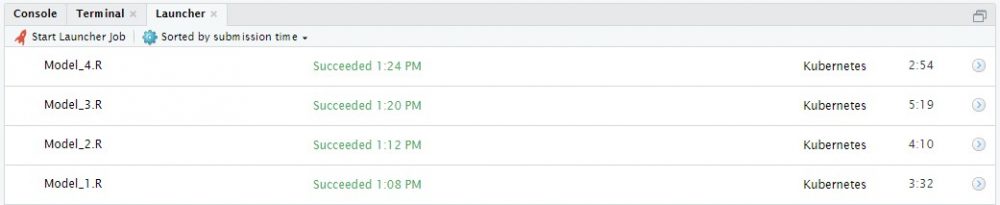
Dadurch werden einerseits Mehrkosten durch Server im Leerlauf verhindert, andererseits werden hiermit aber auch Bottlenecks vorgebeugt, die bei Auslastungsspitzen auf Standardsystemen öfter auftreten können. Aufbauend auf dieser Grundidee, kann der RStudio Job-Launcher auch in lokalen Sessions genutzt werden, in dem einzelne R-Skripte im Kubernetes-Cluster ausgeführt und deren Ergebnisse zurückgespielt werden. Data-Science-Anwendungsfälle hierfür sind die bereits aufgeführten ressourcenaufwändigen Skripte, das simultane Trainieren von unterschiedlichen Analysemodellen oder eben auch Kompilierungsaufgaben, die auf externe Nodes ausgelagert werden können.
Unser Fazit
Die Skalierbarkeit zusammen mit der on-demand Bereitstellung und Nutzung von Ressourcen ist ein idealtypisches Szenario für Unternehmen, die ihre Daten im lokalen Rechenzentrum vorhalten müssen und nicht komplett in die Cloud gehen können. Zusätzlich muss durch das Auslagern von rechenintensiven Prozessen das lokale Rechenzentrum nicht unnötig wachsen. Man erspart sich auf diesem Weg die Anschaffung von zusätzlichen Servern im lokalen Rechenzentrum, welche nur zu temporären Ressourcenpeaks ausgelastet werden.
Unserer Einschätzung nach, wird durch das stetige Datenwachstum und der immer komplexer werdenden Anforderung an die Analyseinfrastruktur, dieses Szenario besonders für Unternehmen interessant sein, die ihre Daten nicht in der Cloud lagern dürfen.
Neben dem Vorteil lokale Daten, die on-premise gehostet werden, in einem Rechencluster zu verarbeiten, können Analysen zudem auch durch Docker Images auf unterschiedlichen Frameworks basieren. Zusätzlich werden flexible Anforderungen an die Analyseinfrastruktur, wie zum Beispiel der Ausführung bestimmter Analysen auf einem GPU- oder CPU-Cluster oder das Hochfahren zusätzlicher Worker Nodes, problemlos realisiert. Rechenintensive Prozesse horizontal zu skalieren, kann auf diesem Wege mit wenig Aufwand erreicht werden, denn der Zugang zu einem Cluster ist einfacher denn je, beispielsweise durch Amazons EKS-Service, welcher ein komplett Cloud-basiertes Kubernetes-Cluster zur Verfügung stellt.
Dieser spezielle Ansatz ist eine Lösung für zahlreiche Herausforderungen für Data Scientists und Data Engineers. Aus diesem Grund unterstützen und beraten wir Sie gerne bei der Planung bzw. Implementierung einer IT-Infrastruktur in Ihrem Unternehmen. Erfahren Sie mehr über unser Analytic Infrastructure Consulting!