Versionsverwaltung – Die unkomplizierte Arbeit am gemeinsamen Projekt
Wer im Jahr 2019 einen Job als Entwickler antritt, sei es in der Softwareentwicklung oder im Bereich Data Science, Data-Ops, etc., der wird zu meist relativ früh mit einem Tool zur Versionsverwaltung konfrontiert. Programme wie Git, SVN und BitKeeper werden primär verwendet, um die Entwicklungshistorie transparent vor- und zurückzuspulen oder neue Features auf separaten Entwicklungszweigen zu entwickeln. Außerdem zeichnet sich die Versionskontrolle für die lineare Skriptentwicklung und das Code Management aus. Auch wenn das zum Einstieg benötigte Vokabular vergleichsweise gering erscheint, so sollte man sich davon nicht täuschen lassen. Für Personen, die zum ersten Mal mit diesen Tools arbeiten, erfordert das Einsteigen ein ungewohntes Denken beim Anwenden. Um produktiv mit den Tools arbeiten zu können, reicht zum Einstieg eine Handvoll Vokabeln, um einen transparenten und konfliktfreien Arbeitsablauf gewährleisten zu können. Neben den gängigen Befehlen bieten alle Tools eine große Funktionsvielfalt, die für spezifische Anwendungsfälle hilfreich sind, aber auch die Komplexität der Arbeitsablaufs erhöhen.
In diesem Artikel geben wir zum einen eine kurze Einführung in die Aufgaben einer Software zur Versionsverwaltung und zum anderen wird eines dieser Tools genauer betrachtet.
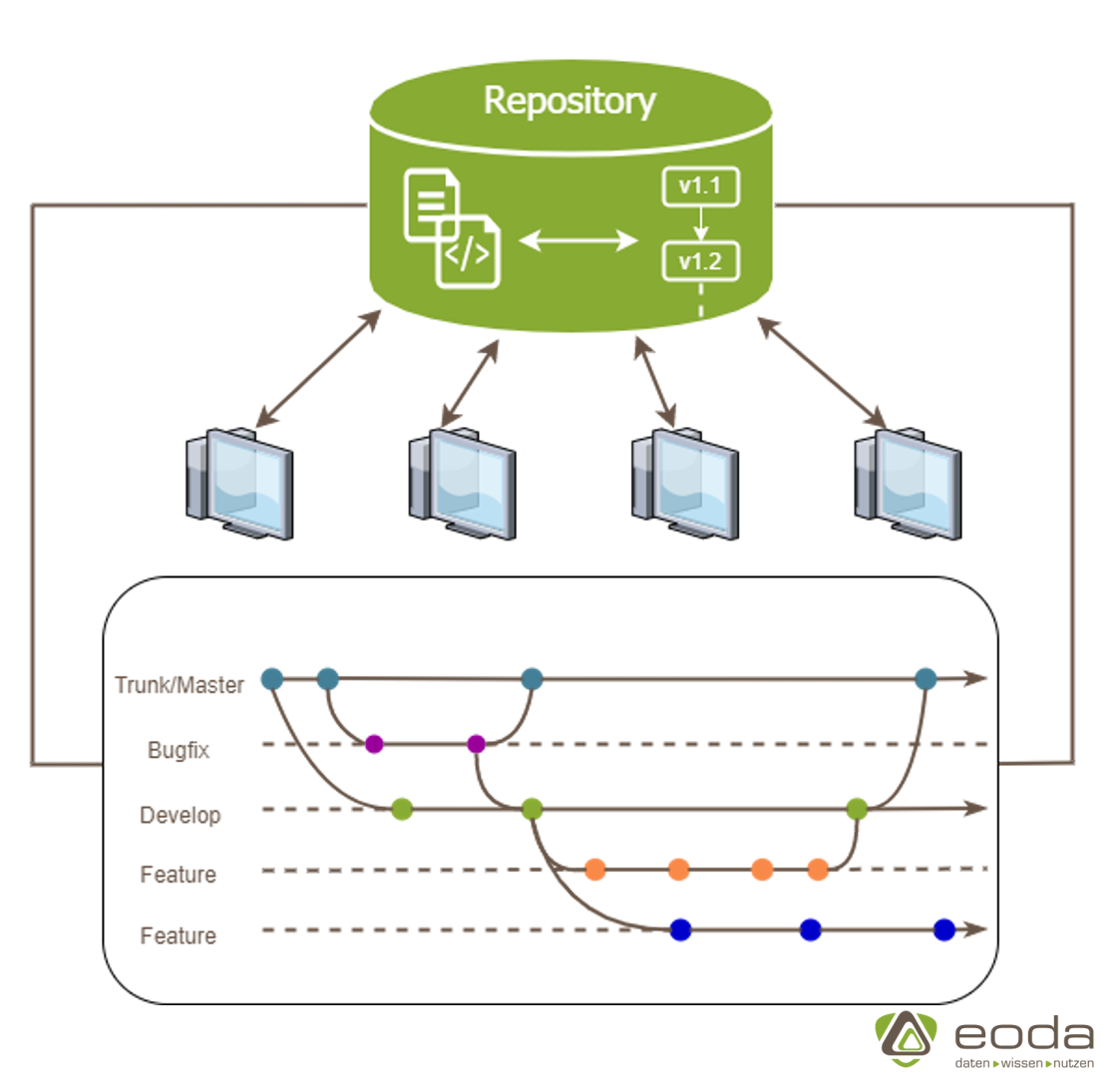
Protokollieren & Archivieren – Der Arbeitsalltag einer Versionsverwaltung
Die grundlegende Arbeitsweise der Versionsverwaltungstools ist recht simpel. In dem Einstiegspunkt, einem (Projekt-)Ordner, werden Änderungen an den Dateien verfolgt. Es werden grundsätzlich nicht alle Dateien auf Änderungen überwacht, sondern nur Dateien die vom Benutzer vorgemerkt oder indexiert sind. Zusätzlich können Dateien explizit auf Entwicklungszweigen vorgemerkt und somit isoliert entwickelt werden. Dieses Vorgehen vermeidet Konflikte, da die anderen Nutzer erst das fertige Feature zu sehen bekommen und sich auf die Entwicklung von ihren Eigenen konzentrieren können, ohne Rücksicht auf potenzielle Änderungen zu nehmen. Somit können jederzeit unterschiedliche Entwicklungsstände des Projektes abgerufen und bei Bedarf widerhergestellt werden.
Der Workflow kann sich dabei wie ein Baum vorgestellt werden. Dieser ist projektübergreifend meist identisch:
- Alle Dateien samt Versionsbaum werden in einem Projektarchiv (Repository) gespeichert. Der Entwickler klont den aktuellen Stand (der symbolischen Referenz) in sein lokales Arbeitsverzeichnis.
- Es existiert ein Hauptzweig, auf dem sich immer eine lauffähige und aktuellste „live“ Version des Projektes befindet (Trunk – SVN / Master – Git). Neben dem Master gibt es einen weiteren Entwicklungszweig „develop“ (nightly build). Es ist ein zusätzlicher Zweig, der bestenfalls (immer) funktionsfähig ist und die aktuellen Produktiv-Features enthält.
- Werden Änderung durchgeführt, so werden diese zunächst auf einem separaten Zweig (Branch) implementiert. Ist der Entwickler mit seinen Änderungen zufrieden, “commited” er seine Änderungen, das heißt, er pflegt seine Änderungen in die Versionsverwaltung ein.
- Damit andere Entwickler auch auf die neuen lokalen Änderungen zugreifen können, wird der bisher lokale Branch durch einen “Push” in dem Remote Repository publiziert. Auf diesem Weg können die Entwickler ihre Entwicklungsstände synchronisieren.
- Ist die Änderung getestet und lauffähig, so kann bei Bedarf der Entwicklerzweig mit dem Hauptzweig zusammengeführt werden (“merge”).
Dezentrale Versionsverwaltung mit Git
Im Gegensatz zur zentralen Versionsverwaltung, in der der Versionsbaum nur in einem zentralen Repository vorhanden ist, hat jeder Entwickler in der dezentralen (verteilten) Versionsverwaltung sein eigenes lokales Repository. Änderungen können dabei im eigenen Repository lokal verfolgt und ggf. mit den Repositories anderer Entwickler abgeglichen werden. Konflikte bei der Arbeit an denselben Dateien zwischen zwei oder mehr Entwicklern müssen dadurch erst dann gelöst werden, wenn die verschiedenen Versionen zu einer zusammengeführt werden sollen. Im Folgenden soll ein möglicher Workflow mit Git vorgestellt werden, eine der populärsten Applikationen zur dezentralen Versionsverwaltung. Hierbei ist anzumerken, dass wir uns auf eine Variante der verteilten Versionsverwaltung beziehen, in der ein offizielles Repository existiert, welches zu Beginn des Projektes geklont wird und auf dem lokale Änderungen zusammengeführt werden. In der Theorie ist dies nicht zwingend nötig, macht aber in den meisten Projekten Sinn.
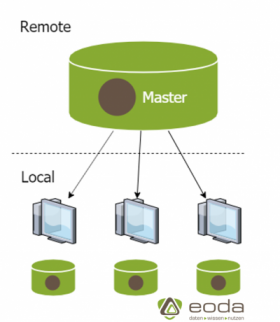
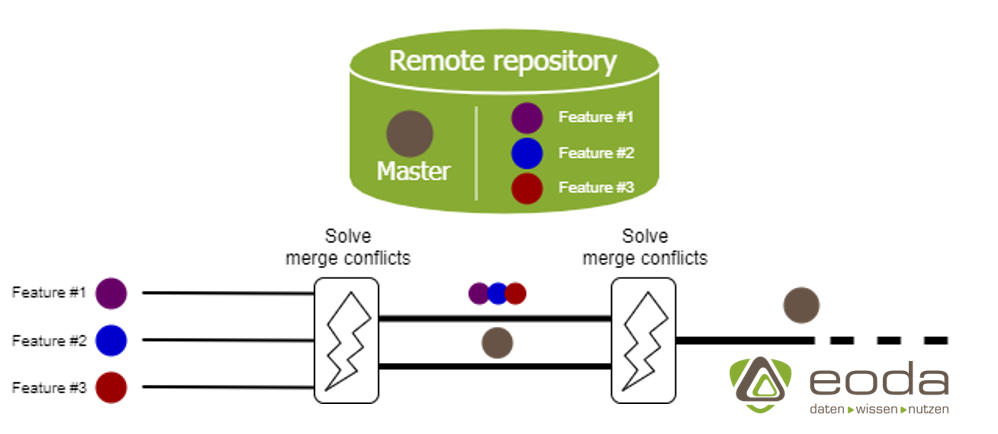
Schritt 1: Erzeugen und Synchronisieren eines Remote Repositorys
Zunächst wird ein offizielles Repository angelegt, auf dass jeder Entwickler Zugriff hat. In diesem befindet sich ein Master-Branch, welche nur dafür da ist, stabile Versionen zur Verfügung zu stellen, welche aus den lokalen Entwicklerversionen zusammengeführt werden. Keiner der Entwickler sollte dabei direkte Änderungen am Master-Branch vornehmen.
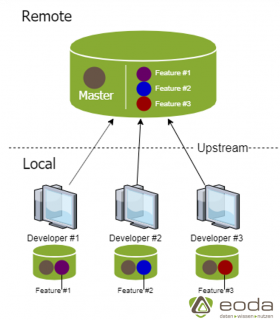
Schritt 2: Erzeugen und Synchronisieren von lokalen Branches
Jeder Entwickler erzeugt lokale Branches, auf denen Features o.Ä. entwickelt werden. Die lokalen Branches werden über einen Upstream mit dem Remote Repository synchronisiert.
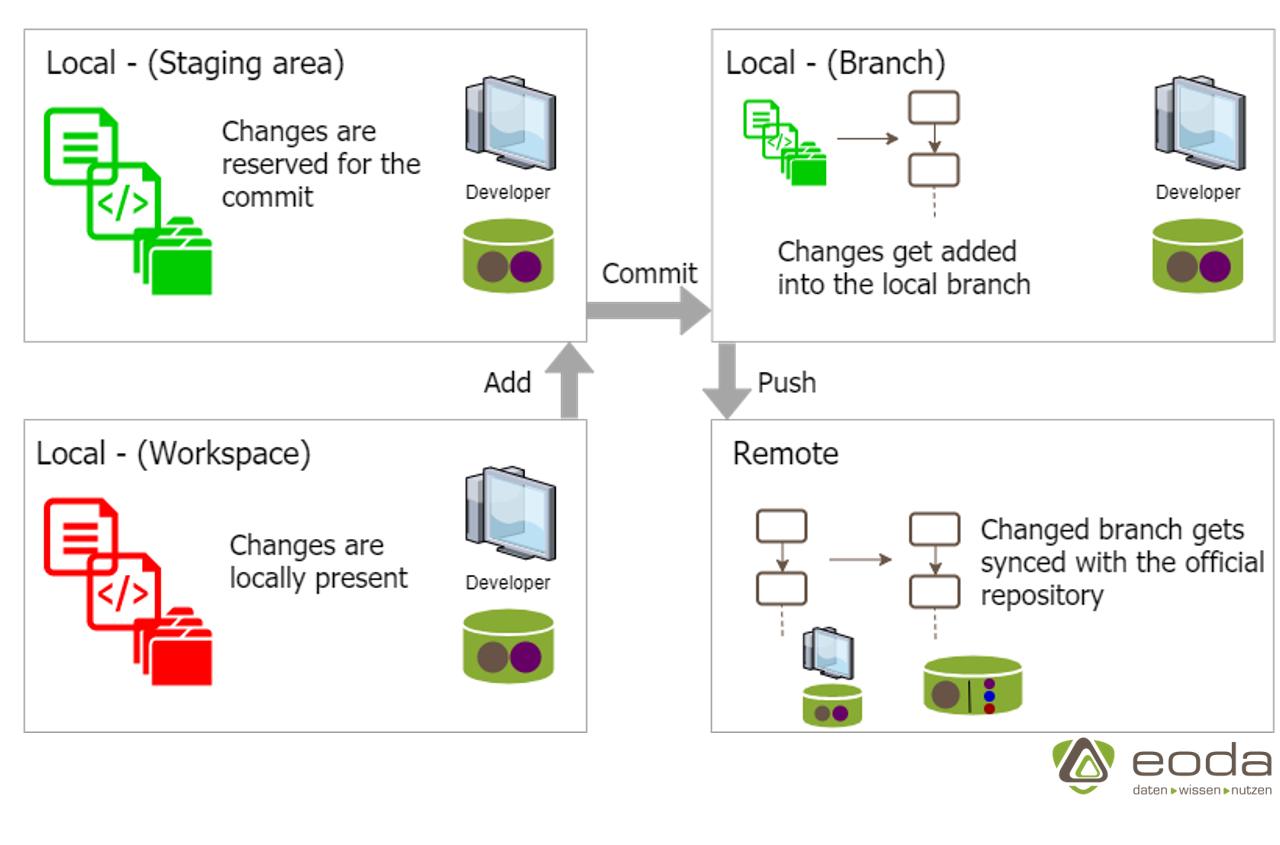
Schritt 3: Änderungen stage/commit/push
Nachdem lokal Veränderungen an Dokumenten/Dateien/Ordnern vorgenommen wurden, müssen diese zunächst “gestaged” werden, was die Änderungen für den nächsten “commit” vormerkt. Nachdem die Änderungen dann durch den “Commit” in den lokalen Branch überführt wurden, wird der Zweig mittels “Push” mit dem Remote Repository synchronisiert.
Schritt 4: Zusammenführen der Entwicklerzweige
Sind alle nötigen Features für eine aktualisierte Version in-place, so können die Entwicklerzweige auf dem Master-Branch zusammengeführt (merge) werden. Hierbei werden potenzielle Konflikte zwischen verschiedenen Branches aufgelöst.
Fazit
Die Versionsverwaltung stellt ein zentrales Tool für das Projektmanagement dar – nicht nur in der Entwicklerbranche. Die Versionierung von Dokumenten findet beinahe in jedem Bereich Anwendung, wenn auch nicht immer mit Tools wie Git oder SVN (z.B. beim gemeinsamen Arbeiten am Word-Dokument). Mit zahlreichen Zusatzapplikation, welche beispielsweise eine GUI zur Versionsverwaltung anbieten (z.B. GitLab für Git) oder im gleichen Zuge bereits eine vollständige CI-Pipeline für das Repository zur Verfügung stellen (z.B. GitLab CI Runner), wird die Arbeit am gemeinsamen Projekt voraussichtlich auch in Zukunft immer einfacher und damit auch zugänglicher werden.
Gern unterstützen wir Sie im Rahmen unseres eoda | analytic infrastructure consulting beim Aufbau einer produktiven Data-Science-Umgebung im Hinblick auf die optimale Versionsverwaltung und viele andere wichtige Aspekte in Ihrem Unternehmen.