Data Science ist in vielen Branchen zu einem der entscheidenden Erfolgsfaktoren geworden. Um für Data Science reibungslose Arbeitsprozesse garantieren zu können, bedarf es der Implementierung einer Architektur, welche die Performance, Agilität und individuellen Rechte der Nutzer berücksichtigt.
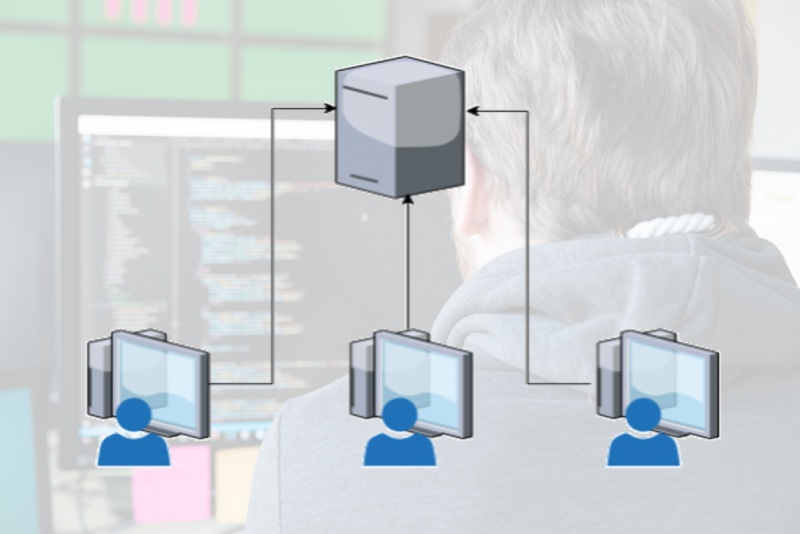
Die Nachteile von Client-Client-Architekturen
Client-Client-Architekturen haben den Charme einer hohen Individualisierbarkeit der einzelnen Rechner: Jede Mitarbeiterin und jeder Mitarbeiter kann den eigenen Client so einrichten wie er möchte. Dies ermöglicht ein unabhängiges Arbeiten, ohne dabei Rücksicht auf die Kolleginnen und Kollegen nehmen zu müssen. Dies klingt zunächst sehr gut, jedoch lassen sich diverse Probleme identifizieren: Arbeiten die Data-Science-Kräfte mit unterschiedlichen Betriebssystemen, müssen dementsprechend spezifische Änderungen an den jeweiligen Dokumenten vorgenommen werden, um diese korrekt auf den Rechnern darstellen zu können. Ein Beispiel dafür sind unterschiedliche Tex-Distributionen auf Windows (MikTex) und Unix (Texlive).
Dieses Problem vertieft sich, wenn man an den Austausch von Dokumenten denkt. Die Konfiguration einer Datenbankverbindung ist meistens vom Betriebssystem abhängig. Sofern die IT eines Unternehmens keine zentralisierten Wartungstätigkeiten vornehmen kann, müssen an den einzelnen Rechnern einer Data-Science-Abteilung diverse Schritte wiederholt durchgeführt werden. Zudem sind diese Desktop-Rechner oder Laptops nicht für High-Performance-Computing ausgelegt.
Client-Server-Architekturen als Lösungsansatz
Wer kennt als Data Scientist nicht folgendes Szenario: Man beendet die Projektaufgabe zum Beispiel der Geschäftsführung einen Tag vor Abgabe und ist sich sicher, dass der getestete Code bei der Vorstellung ebenfalls einwandfrei funktionieren wird. Aus leidvoller Erfahrung weiß man, dass dies leider nicht immer der Fall ist.
Sobald Daten zwischen unterschiedlichen Client-Rechnern verschoben werden, sind die unterschiedlichen Paketversionen oft das kleinste Problem, denn oftmals wird vernachlässigt, dass…
- Grafiken bei den verschiedenen Betriebssystemen (Unix, Windows, MacOs) unterschiedlich gerendert und dadurch verzerrt dargestellt werden.
- die zu generierten PDF Reports auf unterschiedlichen Tex Repositories basieren, sofern mit Windows und Unix gearbeitet wird (MikTex, TexLive) und diese auf dem fremden System zunächst zur Verfügung gestellt werden müssen.
- die Variablen, die in der Datenbank hinterlegt wurden, nur für diesen einen Nutzer funktionieren und nicht für die Geschäftsführung.
- die Datenbankverbindung beispielsweise zu einer Oracle Datenbank konfiguriert werden müssen
Um diesen Hindernissen im Produktivbetrieb entgegenzuwirken, empfiehlt sich der Wechsel hin zu einer Client-Server-Architektur. Server bieten in der Regel mehr Leistung als Desktoprechner, lassen sich zentral warten und dementsprechend aufrüsten. Diese Aspekte bieten einen immensen Vorteil bei der Wartung der Infrastruktur sowie der angeschlossenen Komponenten, da es ein „one and done job“ ist. Ebenfalls wird der Austausch von Daten zwischen den Kollegen vereinfacht, da alle beteiligten Akteure auf dem gleichen System arbeiten und somit auf die gleichen Ressourcen und Bibliotheken zugreifen können.
Die Vorteile von Client-Server-Architekturen
Der größte Vorteil, den die Client-Server-Architektur mit sich bringt, ist die einmalige serverseitige Lösung. Dies gilt ebenfalls für Updates, die einmalig und zentral auf dem Server durchgeführt werden und danach für alle Clients verfügbar sind.
Zudem bieten Client-Server Architekturen viele weitere Vorteile. Die von Data Scientists verwendeten Tools sind standardisiert und stehen den Mitarbeiterinnen und Mitarbeitern einsatzbereit und vorkonfiguriert zur Verfügung. Zudem lassen sich die Zugänge der Clients auf dem Server verschlüsselt verwalten, sodass „plain text credentials“ (Texte ohne Verschlüsselung) kein Compliance-Problem werden. Ein weiterer Vorteil der Client-Server Architekturen, ist die Grafikerstellung. Die erzeugten Grafiken sind aufgrund des gleichen Betriebssystems uniform und können demnach frei verwendet werden. Da alle Anfragen auf dem Server durchgeführt werden, fehlen keine Bibliotheken auf einem Client. Dies ermöglicht eine problemlose Erstellung von Reports, welche auf allen Systemen erzeugt werden können. Neben der standardisierten Software sind ebenfalls die Pakete einheitlich. Dies bedeutet, dass das Problem, dass eine Analyse mit den Paketen A, B und C nur auf Betriebssystem B geschrieben wird und ausschließlich dort funktioniert, Vergangenheit ist. Weiterhin besteht die Möglichkeit, durch eine zentrale Prüfstelle neue Pakete zu evaluieren, bevor sie unternehmensweit ausgerollt werden. Nicht zuletzt bieten Server einen größeren Ressourcenpool als lokale Desktoprechner, da sie als „Central Processing Unit (CPU)“ (Hauptprozessor) und „Random-Access Memory (RAM)“ (Datenspeicher) agieren. Dies ermöglicht eine deutlich performantere Analyse von Daten.
Zusammenfassend lässt sich sagen, dass die Implementierung einer Analyse-Umgebung auf Basis einer Client-Server-Architektur in vielen Fällen Vorteile mit sich bringt. Die Architektur kann entscheidende Auswirkungen auf die Performance, Agilität, Verwaltung sowie auf die individuellen Berechtigungen der Nutzer haben und zum Beispiel den Datenaustausch innerhalb eines Unternehmens deutlich vereinfachen.
Erfahren Sie mehr.