Stellen Sie sich vor, Sie möchten sich ein neues Auto kaufen und sammeln demnach alle möglichen Informationen rund um das Thema. Die Recherche geht von Marken- und Preisvergleichen auf diversen Onlineportalen bis hin zu der Analyse von Forenbeiträgen über Ausstattung und Technik-Features. Zudem werden Familienangehörige, Freunde sowie Auto-Interessierte im Bekanntenkreis nach der Meinung gefragt. Mit anderen Worten: Sie stolzieren nicht in das nächstgelegene Autohaus und kaufen das erste Auto was Sie sehen, sondern treffen eine Entscheidung anhand der Auswertung der gesammelten Informationen. Dieser Prozess spiegelt den Grundgedanken hinter dem Ensemble Modelling wider: das Zusammenführen von unterschiedlichen Informationen für ein möglichst genaues, standardisiertes Ergebnis. Doch was für ein Auswertungsschema sollte genutzt werden damit dies umgesetzt werden kann?
Dem Data-Science-Kontext nach entsprechen die unterschiedlichen Informationsstränge Datensätzen, mit denen Algorithmen trainiert werden. Bestimmte Algorithmen neigen dazu Daten zu overfitten, d.h. alle Informationen zu verwerten und mit höchster Genauigkeit wiederzugeben. Das Gegenteil des Overfittings, das sogenannte Underfitting, findet bei einer Unteranpassung der Daten statt. Damit präzise Ergebnisse erreicht werden können, wird hierbei auf eine Zusammensetzung von maschinellen Lernalgorithmen gesetzt.
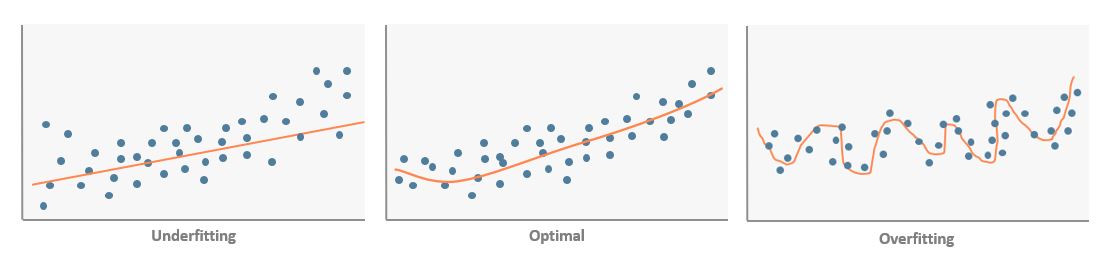
Das Ziel von Ensemble Modeling, oder auch Ensemble Learning, ist es mit einer Gesamtheit (franz. Ensemble) von Algorithmen sowohl genaue als auch generalisierbare Modelle zu bilden. Diese Modelle sollen in der Lage sein, Daten aus kumulierten Lernalgorithmen zu entnehmen und durch einen Trade-Off zwischen generalisierbaren und genauen Modellen einen Mittelwert abzubilden. Der Hintergrund für den Einsatz der Ensemble-Methoden ist, dass eine Gruppe von Algorithmen in vielen Fällen ein präziseres Ergebnis erzielen kann, als es ein einzelner Algorithmus könnte.
Eine der weitverbreitetsten Techniken ist das Bagging welches für Bootstrap Aggregation steht. Bagging ermöglicht das parallele Trainieren eines Algorithmus mit Daten, die unterschiedlich aufgeteilt werden. Auf sogenannten Bootstrap-Stichproben werden jeweils separate Modelle gebildet. Dabei erfolgt das Trainieren der Modelle auf unterschiedliche Stichproben, bei denen Abweichungen vorkommen können. Einzelne Stichproben, die die Algorithmen generieren, werden miteinander verbunden und auf einen Mittelwert gebracht. Durch die Analyse aller Kombinationen und die Zusammenführung der Ergebnisse, können so Unsicherheiten reduziert werden. Da nun alle Modelle gemeinsam arbeiten, sozusagen ineinander greifen, werden Über- und Unteranpassungen reduziert, um ein valides Ergebnis zu erreichen.
Noch erwähnt sei ein sehr beliebter Machine-Learning-Algorithmus, welcher Bagging verwendet: Random Forest. Dieser Algorithmus nutzt Bagging um eine Vielzahl an Entscheidungsbäumen zu erstellen. Dabei gibt Random Forest jedem Baum nur eine Teilauswahl an zu wählenden Variablen vor, um zu vermeiden, dass sich die Bäume über die einzelnen Stichproben hinweg zu stark ähneln. Am Ende dieses Verfahrens ist ein Overfitting für jede Vorhersage gemacht worden, doch das Ergebnis bleibt über alle einzelnen Bäume hinweg sehr robust.
Eine Alternative ist das Boosting: Hierbei geht es darum Algorithmen sequentiell auf das jeweils vorherige Modell zyklisch aufzubauen – so sollen die Fehler des jeweiligen vorherigen Modells bereinigt werden. Algorithmen wie zum Beispiel Gradient Boosting setzen in diesem Schritt den Fokus darauf, die vom vorherigen Modell begangenen Fehler nachzuvollziehen und im nächsten Modell „bevorzugt“ gut zu modellieren. Schwache Verfahren sollen, indem sie an gewichtete Versionen angepasst werden, so aufeinander Bezug nehmen, damit am Ende die Genauigkeit maximiert wird. Dabei spielt es keine Rolle, dass die Modelle von Anfang an möglichst genau sein sollen – im Gegenteil: Sie funktionieren sogar weitaus besser mit flachen bzw. kurzen Entscheidungsbäumen, die als schwächere Modelle eingestuft werden. Die Fehler, die sich nach einer Runde ergeben, werden höher gewichtet. Auf diese Weise werden grundlegende Fehler identifiziert und minimiert. Jedoch besteht hierbei die Gefahr des Overfittings. Während Bagging die Unsicherheit der Modelle reduziert, versucht Boosting die Maximalgenauigkeit zu erhöhen.
Beim Methodenansatz Stacking hingegen werden unterschiedliche Ergebnisse von verschiedenen Algorithmen genutzt und zusammengefasst. Diese Vorgehensweise wird genutzt um Over- b zw. Underfitting zu vermeiden. Die Ergebnisse werden dann durch Einsatz weiterer Methoden zusammengefasst. Diese können z.B. das arithmetische Mittel oder eine logistische Regression sein.
Die Komplexität und das Zusammenspiel solcher Modelle erschwert natürlich die Nachvollziehbarkeit der ablaufenden Prozesse. Nichtsdestotrotz ist der Einsatz von Ensemble Modeling eine sehr gute Möglichkeit die Schwächen einzelner Algorithmen abzufangen.