Dienstag, 29.05.2018
R , Julia, Python – Den Datenwissenschaftlern von heute stehen zahlreiche verschiedene Programmiersprachen zur Verfügung, alle mit ihren eigenen Stärken und Schwächen. Wie praktisch wäre es da, wenn man die Sprachen zusammenführen könnte, um so die individuellen Stärken einer jeden Sprache nutzen zu können? Das reticulate-Package für R geht einen großen Schritt in diese Richtung.
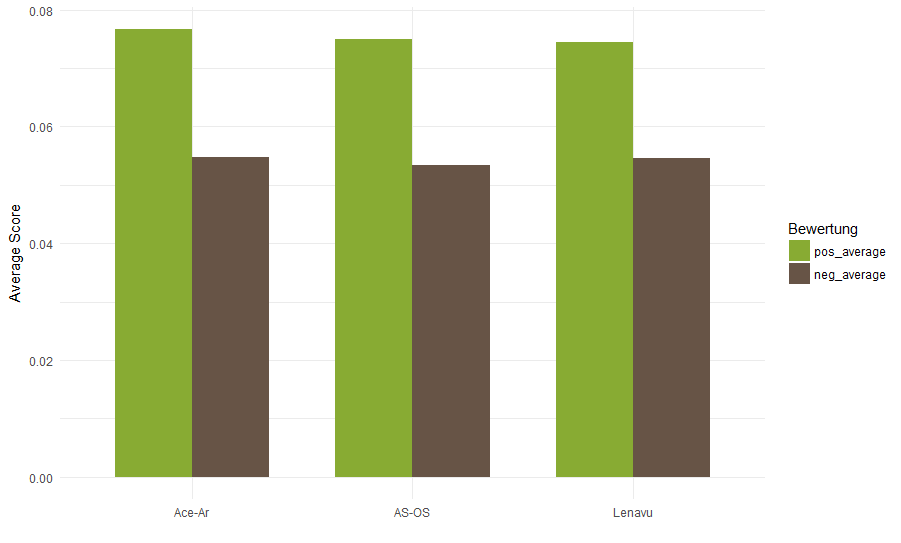
Es schafft eine Python-Anbindung für R und lässt den Benutzer beide Sprachen für ein optimales Ergebnis kombinieren. Besonderen Bezug wollen wir auf die von reticulate implementierte Python-Engine für R-Markdown nehmen und anhand eines tutorial-ähnlichen Leitfadens den Grundgedanken, die Funktionsweise sowie die Nützlichkeit der Engine verdeutlichen.
The weapon of choice – Datenanalyse im Arbeitsalltag
Es könnte alles so einfach sein: Jeder spricht dieselbe Sprache, Grenzen verblassen und die Zusammenarbeit ist so einfach wie nie zuvor. Was hier zugegebener Weise etwas dramatisch klingt, spiegelt sich immer öfter im Alltag eines Data Scientists wieder. Wo R auf der statistischen Seite seine Stärken ausspielen kann, wird auch die Multi-Purpose Sprache Python im Data-Science-Kontext immer beliebter und aufgrund ihrer Multifunktionalität immer häufiger zur Sprache der Wahl. Es scheint also zwingend nötig, die Brücke zwischen beiden Sprachen zu schlagen und ihnen damit gemeinsamen Raum innerhalb eines Projektes zu schaffen.
Die virtuelle Brücke – Das reticulate-Package
Das reticulate-Package stellt eine Python-Anbindung für R zur Verfügung. Benutzer können damit Python-Code direkt aus der R-Konsole ausführen, Python-Skripte in die R-Umgebung laden und so für R benutzbar machen. Außerdem liefert reticulate eine Python-Engine für R-Markdown gleich mit, welche in folgenden Beispielen näher betrachtet werden soll.
Einführung – Setup & Python-Chunks in R-Markdown
Das Setup von reticulate gestaltet sich sehr simpel. Nachdem das Paket sowie die bevorzugte Python-Distribution ( 2.7x oder 3.x ) installiert wurde, kann mit
library(reticulate)<br /> knitr::knit_engines$set(python = reticulate::eng_python)
die Python-Engine initialisiert werden. Die Code-Chunks funktionieren wie gewohnt und alle Optionen der R-Chunks können auch für die Python-Chunks benutzt werden.
Zum Beispiel schafft
```{r testChunk_R, warning = FALSE, message = FALSE}
Code
```
einen R-Chunk und
``{python TestChunk_Py, warning = FALSE, message = FALSE}
Code
```
einen Python-Chunk. Aber Achtung: Der im Python-Chunk ausgeführte Code wird nicht in die globale Umgebung geladen! Zugriff von außerhalb auf Funktionen und/oder Variablen erhält man nur, wenn knit ausgeführt wird. Die alleinige Ausführung des Chunks reicht nicht. In unserem zugehörigen HTML-Notebook finden sich weitere Beispiele zur Implementierung von Funktionen in den verschiedenen Sprachen.
Weiterführung – Automatisierte Typkonvertierung und Interkonnektivität
Für sich genommen schafft reticulate damit schon eine angemessene Brücke zwischen den beiden Sprachen. Entwickler können so mit unterschiedlichen Programmierkenntnissen im gleichen Dokument am gleichen Projekt arbeiten, ohne dass Code übersetzt werden muss. Ferner können so die Stärken beider Sprachen ausgenutzt werden. Um die Grenzen noch weiter aufzulockern, stellt reticulate außerdem die Möglichkeit zur Verfügung, innerhalb des Chunks einer Sprache auf Variablen der anderen Sprache zuzugreifen. Folgender Code-Ausschnitt soll diese funktionsweise verdeutlichen:
```{r chunk1_R}
test_vector <– c(1, 2, 4, 4, 7, 3, 5)
```
```{python chunk1_Py}
num_four = r.test_vector.count(4)
print „Der Vektor enthält “, num_four, „ mal die Zahl 4“
```
```{r chunk2_R}
out_string = paste(„Richtig, der Vektor enthält“, py$num_four, „mal die Zahl 4“)
print(out_string)
```
Reticulate passt dabei automatisch die Typen für die jeweilige Sprache an. Liest chunk1_Py beispielsweise test_vector ein, so wird dieser vom R-Typ Vektor in den äquivalenten Python-Typ Liste umgewandelt. Weitere Typzuordnungen finden Sie hier.
Source_Python – Der „Schatz“ unter den Funktionen
Die Möglichkeit, Python-Code direkt im Dokument zu implementieren und sprachenübergreifend zu verwenden, liefert uns bereits ein mächtiges Tool zur nahtlosen Zusammenarbeit. Der wahre „Schatz“ unter den Funktionen im reticulate-Paket findet sich aber in der Funktion source_python. Diese Funktion liest ein Python-Skript ein und stellt dessen Funktionen und Variablen für beide Sprachen innerhalb des Markdown-Dokumentes zur Verfügung. Diese Funktionsweise soll in folgendem Beispiel verdeutlicht werden:
// Datei bubblesort.py def bsort(numbers): if(isinstance(numbers, list) == False or all(isinstance(p, (int, float)) for p in numbers) == False or len(numbers) == 0): print „Warning: Input must be of Type List, only numeric and have length >= 1“ return for i in reversed(range(1, len(numbers))): for j in range(0, i): if(numbers[j] > numbers[j+1]): numbers = swap(numbers, j, j+1) return numbers def swap(numbers, id1, id2): temp = numbers[id1] numbers[id1] = numbers[id2] numbers[id2] = temp return numbers // Markdown Dokument ```{r setup_script} source_python(„bubblesort.py“) ``` ```{r sort_R} bsort(c(4, 3, 2, 1)) ``` Output: 1, 2, 3, 4 ```{python sort_Py} print bsort([4,3,2,1]) ```
Output: 1,2,3,4
Das Python-Skript bubblesort.py implementiert den Sortieralgorithmus bubblesort unter der Funktion bsort(numbers). Diese Implementation wird dann im Markdown-Dokument mit source_python(„bubblesort.py“) zur Verfügung gestellt und kann, wie oben zu sehen, von beiden Sprachen genutzt werden.
Mit diesem Feature räumt reticulate auch die letzten noch vorhandenen Grenzen aus dem Weg. Entwickler können so komplett in ihrer präferierten Entwicklungsumgebung arbeiten und die Ergebnisse am Ende in ein finales Dokument zusammenführen. Bereits vorhandene Python-Skripte (z.B. Skripte zur Datenbankanbindung, DeepLearning-Algorithmen, etc.) können nahtlos übernommen werden.
Use Case – Textmining mit Vorarbeit
Wir betrachten folgenden fiktiven Use-Case: Elektrofachhändler Elektro-X will einen Werbevertrag mit einem der drei Händler Lenavu, Ace-Ar und AS-OS abschließen. Um sich ein genaueres Bild der Zufriedenheit bezüglich der Händler zu schaffen, startet Elektro-X ein in Python implementiertes Textmining-Projekt: Shop-Reviews werden eingelesen und Rezensionen für die Produkte der Händler durchsucht. Außerdem wird noch eine Funktion zur Errechnung eines Durchschnittsratings für eine Menge an Reviews zur Verfügung gestellt. Da Elektro-X aufgrund von Zeitgründen das Projekt nicht fertigstellen kann, übergibt er seine bisher geleistete Arbeit an eoda und beauftragt uns damit, sein Projekt zu vervollständigen. eoda vervollständigt die Analyse in R, um Zugriff auf ggplot für die Visualisierung zu erhalten, und verwendet dabei die bereits geleistete Vorarbeit in Python.Wir übertragen das Projekt in R unter Zuhilfenahme des reticulate-Packages und benutzen R zur Visualisierung der Bewertungen sowie zur Sentimentanalyse.
Fazit – Die Zukunft von Big Data
Abschließend bleibt nur zu sagen, dass Pakete wie reticulate das Potenzial haben, die Arbeitsweise und damit auch die Zukunft der Big Data Branche maßgeblich zu beeinflussen. Insbesondere Dienstleister wie eoda können von der barrierefreien Kollaboration mit ihren Kunden profitieren, da man sich deutlich schneller den Kernproblemen widmen kann, ohne vorher noch mögliche Umstandsprobleme aus dem Weg schaffen zu müssen. Wer also auch in Zukunft durchgehend effiziente Arbeit in Kundenprojekten leisten können will, sollte bereits jetzt beginnen, sich mit Lösungen zur Problematik der Sprachbarriere, wie reticulate, zu beschäftigen.