Data Science zeichnet sich unter anderem durch das Verwenden von Open Source Tools aus. Ein Vorteil beim Arbeiten mit Open Source Skriptsprachen, wie z.B. R oder Python, ist die große Paketwelt. Diese liefert durch die Entwicklung innerhalb riesiger Communities Werkzeuge für zahlreiche Anwendungsfälle und Problemstellungen. Dabei sind die Pakete in digitalen Online-Archiven – sogenannten Repositories – organisiert. Data Scientists können über diese Repositories auf die aktuellen oder vergangenen Paketversionen zugreifen und diese für ihre Arbeit benutzen. Ein wichtiger Aspekt dabei ist die kontinuierliche Weiterentwicklung vieler Pakete. Neue Paketversionen weisen unter anderem neue, verbesserte oder erweiterte Funktionalitäten sowie Bugfixes auf. In manchen Fällen beinhaltet eine neue Paketversion allerdings auch unterschiedliches Verhalten bei gleichbleibendem Code oder neue Abhängigkeiten zu anderen Paketen, der Programmiersprache selbst oder anderen Systemkomponenten, wie bspw. dem zugrundeliegenden Betriebssystem. Solche Veränderungen erfordern zusätzliche Anpassungen, um die Funktionalität des bereits entwickelten Codes weiterhin zu gewährleisten. So muss der Code beispielsweise auf neue Verhaltensweisen der Pakete angepasst werden oder weitere Pakete müssen installiert werden, um den Abhängigkeiten gerecht zu werden. Vor allem in Produktivsystemen, die nicht nur eine nahezu ständige Funktionalität garantieren müssten, sondern an denen oftmals eine Vielzahl von Entwicklern arbeiten, ist es wichtig, dass Updates der Paketlandschaft schnell und problemlos durchgeführt werden.
Paketmanagement und kollaboratives Arbeiten
Im Idealfall arbeiten alle Entwickler in identischen Umgebungen, also mit den gleichen Paketen und Paketversionen. Arbeiten die Entwickler jedoch mit unterschiedlichen Paketversionen, bei denen es Änderungen von den Entwicklern genutzten Funktionalitäten gibt, entstehen möglicherweise unterschiedliche Skripte und Analysen. Diese funktionieren dann nicht einheitlich bei allen Entwicklern, wodurch entweder Fehler verursacht oder unterschiedliche Ergebnisse geliefert werden. Zusätzlich zu der Gefahr, dass Skripte ein anderes Verhalten in den verschiedenen Umgebungen der Entwickler aufweisen, besteht die Gefahr, dass die Paketversionen der Entwickler von denen des Produktivsystems abweichen, in dem die Analysen gewinnbringend eingesetzt werden und somit nahezu ständig funktionieren müssen. Um Konflikte zwischen unterschiedlichen Paketversionen in der Entwicklung zu vermeiden, versucht man mit einer guten Infrastruktur für ein reibungsloses Paketmanagement zu sorgen, welches gleiche Entwicklungsbedingungen und geregelte und synchrone Updates garantiert.
Eine erste Maßnahme, um die Grundlage für ein gutes Paketmanagement zu schaffen, ist die Bereitstellung von Paketen in einem lokalen, unternehmens- oder teamweiten Repository. Das lokale Repository funktioniert für die Entwickler wie ein Online-Repository, wobei im lokalen Repository nur ausgewählte Pakete und Paketversionen zur Verfügung stehen. Somit haben alle Data Scientists Zugriff auf das gleiche zentrale Paketarchiv, während gleichzeitig sichergestellt werden kann, dass die Paketversionen im Repository weitestgehend stabil sind und alle Abhängigkeiten erfüllt sind. Somit wird vor allem garantiert, dass sich die entwickelten Algorithmen bzw. der Code unternehmensweit in den verschiedenen Entwicklungsumgebungen und im Produktivsystem gleich verhalten. Allerdings kann dabei nicht immer die Koexistenz von unterschiedlichen Versionen des gleichen Pakets gewährleistet werden, da somit wieder die Gefahr wie im Falle eines Online-Repositories besteht, also, dass verschiedene Entwickler auf unterschiedlichen Paketversionen entwickeln. Hierfür eignet sich der RStudio Package Manager. Der RStudio Package Manager agiert als Brücke, um verschiedene Paketquellen, wie z.B. Online Repository, Local Repository und u.a. externes Entwicklungs-Repository (GitLab) miteinzubinden. Unternehmen mit restriktiven Corporate-Governance-Grundsätzen wollen lediglich eine abgesegnete Teilmenge der Pakete in ihrem lokalem Repository haben.
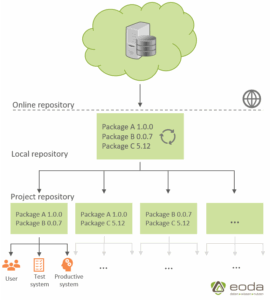
Um diesem Problem vorzubeugen, kann man auch das lokale Repository um unterschiedliche Paketversionen erweitern und die Einschränkung auf eine bestimmte Version innerhalb unterschiedlicher Projekte gewährleisten. Dafür wird für jedes Projekt eine Projektumgebung definiert, die einen bestimmten Teil der Pakete des lokalen Repositories enthält und auf fixe Paketversionen beschränkt ist. Dies hat den Vorteil, dass in unterschiedlichen Projekten mit unterschiedlichen Paketen bzw. Paketversionen gearbeitet werden kann, während man innerhalb eines Projekts eine projektweit stabile und konfliktfreie Paketwelt bereitstellt. Für die Data Scientists bedeutet das entweder die Entwicklung auf einem zentralen Entwicklungssystem (bspw. einem RStudio-Server) oder auf ihrem lokalen System mit den für das Projekt definierten Paketen zu arbeiten (bspw. als R-Projekt oder conda environment, wahlweise innerhalb eines Docker Containers). Zusätzlich wird ein Produktivsystem betrieben, welches eine zu der Entwicklungsumgebung identische Paketlandschaft umfasst. In diesem Fall stellt das lokale Repository vor allem eine zusätzliche Sicherheitsebene dar, um nur Pakete zur Verfügung zu stellen, die sich über einen gewissen Zeitraum als stabil erwiesen haben und die möglicherweise bereits erste Bugfixes enthalten.
Ist es an der Zeit ein Update der Pakete durchzuführen, sollte dies nahezu zeitgleich auf den Entwicklungs- und Produktivumgebungen geschehen, um ein unterschiedliches Verhalten der Umgebungen auf einen möglichst kleinen Zeitraum zu beschränken. Es ist besonders wichtig, dass das Produktivsystem ohne Unterbrechungen stabil läuft. Daher empfiehlt es sich ein Testsystem einzurichten, auf dem die Updates zuvor durchgeführt werden, um fehlende Paketabhängigkeiten oder Konflikte zwischen bestimmten Paketversionen zu prüfen. Hat man auf dem Testsystem einen stabilen Zustand erreicht, kann man zunächst die Entwicklungsumgebungen updaten, um gegebenenfalls die Algorithmen und Analysen auf die neuen Paketversionen anzupassen. Ein Update der Paketwelt auf dem Produktivsystem kann dann zeitgleich mit den bereits auf den Entwicklungsumgebungen getesteten Anpassungen der Analysen geschehen, um das Fehlerrisiko auf dem Produktivsystem so gering wie möglich zu halten. Um solche Updates regelmäßig schnell und problemlose durchzuführen, ist eine verlässliche Infrastruktur von großer Bedeutung. Dabei hängt der Aufbau einer solchen Infrastruktur von vielen Faktoren ab, wie zum Beispiel Anzahl der Projekte, Größe der Entwicklerteams oder Länge der Updatezyklen.
Ein gutes Paketmanagement in Produktivsystemen und eine vollkommen funktionsfähige Infrastruktur sind die Grundlage für eine komplikationsfreie Entwicklungsumgebung. Gern unterstützen und beraten wir Sie bei der Planung bzw. Implementierung einer IT-Infrastruktur in Ihrem Unternehmen. Erfahren Sie mehr über eoda | analytic infrastructure consulting!
Author
Starten Sie jetzt durch:
Wir freuen uns auf den Austausch mit Ihnen.