
Augmented Intelligence – KI trifft menschliche Expertise in der Markenprüfung
Wie lassen sich hochkomplexe Entscheidungsprozesse durch Künstliche Intelligenz ergänzen, verbessern und vereinfachen? Genau das zeigen wir mit einem Beispiel aus der Realität: Der Prüfung und dem Schutz von Marken.

Augmented Intelligence – KI trifft menschliche Expertise in der Markenprüfung
Wie lassen sich hochkomplexe Entscheidungsprozesse durch Künstliche Intelligenz ergänzen, verbessern und vereinfachen? Genau das zeigen wir mit einem Beispiel aus der Realität: Der Prüfung und dem Schutz von Marken.
Die Prüfung, ob eine Marke geschützt werden kann, ist ein komplexer und zeitaufwendiger Prozess, der tiefgreifendes Fachwissen und viel Recherche erfordert. Dabei wählen die Prüfpersonen in einem System die passenden Nizza-Klassifikationen (wie beispielsweise Klasse 30: „Kaffee, Tee, Kakao, Reis, Gewürze“) aus. Anschließend wird der zu schützende Begriff über eine Suchfunktion mit ähnlichen Bezeichnungen verglichen. Zusätzlich ist es notwendig, den Begriff auf geografische Bezüge, anwendbare Gesetze und Abkommen sowie bereits ähnliche frühere Entscheidungen zu überprüfen. All diese Schritte basierten auf der manuellen Auswahl der jeweiligen Informationsquellen.
Doch was wäre, wenn Künstliche Intelligenz (KI) diese Aufgabe vereinfachen und Fachpersonen entlasten könnte? Genau das ist das Ziel eines innovativen Proof of Concepts (PoC) von eoda, welcher gemeinsam mit dem Eidgenössischem Institut für Geistiges Eigentum (IGE | IPI) entstanden ist: Die Entwicklung eines RAG-basierten Assistenzsystems, das die Markenprüfung vereinfachen soll.
Kleiner Spoiler: Dabei geht es nicht um reine Automatisierung, denn die Expertise der Prüferinnen und Prüfer ist hier nicht zu ersetzen – sie sind die letzte Instanz bei der Eintragung des Markenschutzes.
Ein iterativer Entwicklungsprozess
Jeder Use Case ist individuell, sei es bezüglich Datengrundlage, des Prozesses selbst oder der IT-Infrastruktur. „One size fits all“-Ansätze, also universelle Lösungen, liefern daher, sofern sie überhaupt existieren, nicht die optimalen Ergebnisse. Unsere über 15 Jahre Erfahrung in Data-Science- und KI-Projekten zeigen, dass ein iteratives Vorgehen, besonders bei komplexen Prozessen, die besten Ergebnisse schafft. Zusammen mit einer agilen Herangehensweise und enger Zusammenarbeit mit den Projektteams beider Seiten lassen sich so in kurzer Zeit verschiedene Komponenten testen, um die bestmögliche Kombination zu finden.
Startschuss
Bei der Markenprüfung geht es um den Schutz geistigen Eigentums. Wegen dieser sensiblen Datenbasis erfolgte die Umsetzung des Projektes komplett On-Premise. Wie bei vielen Data-Science- und KI-Projekten begann auch dieses RAG-Projekt mit zwei klassischen Elementen:
- Einer explorativen Datenanalyse der Dokumentengrundlage.
- Der Definition einer zentralen Metrik: dem Recall.
Der Fokus auf den Recall war eine bewusste Entscheidung, da die Expertinnen und Experten die finale Entscheidung treffen und die Relevanz der gefundenen Informationen auf Basis ihrer Erfahrung besser beurteilen können. Um die Effektivität des Systems zu überprüfen, erstellte die Fachabteilung zudem einen Evaluationsdatensatz mit tatsächlichen Prüfungsresultaten.
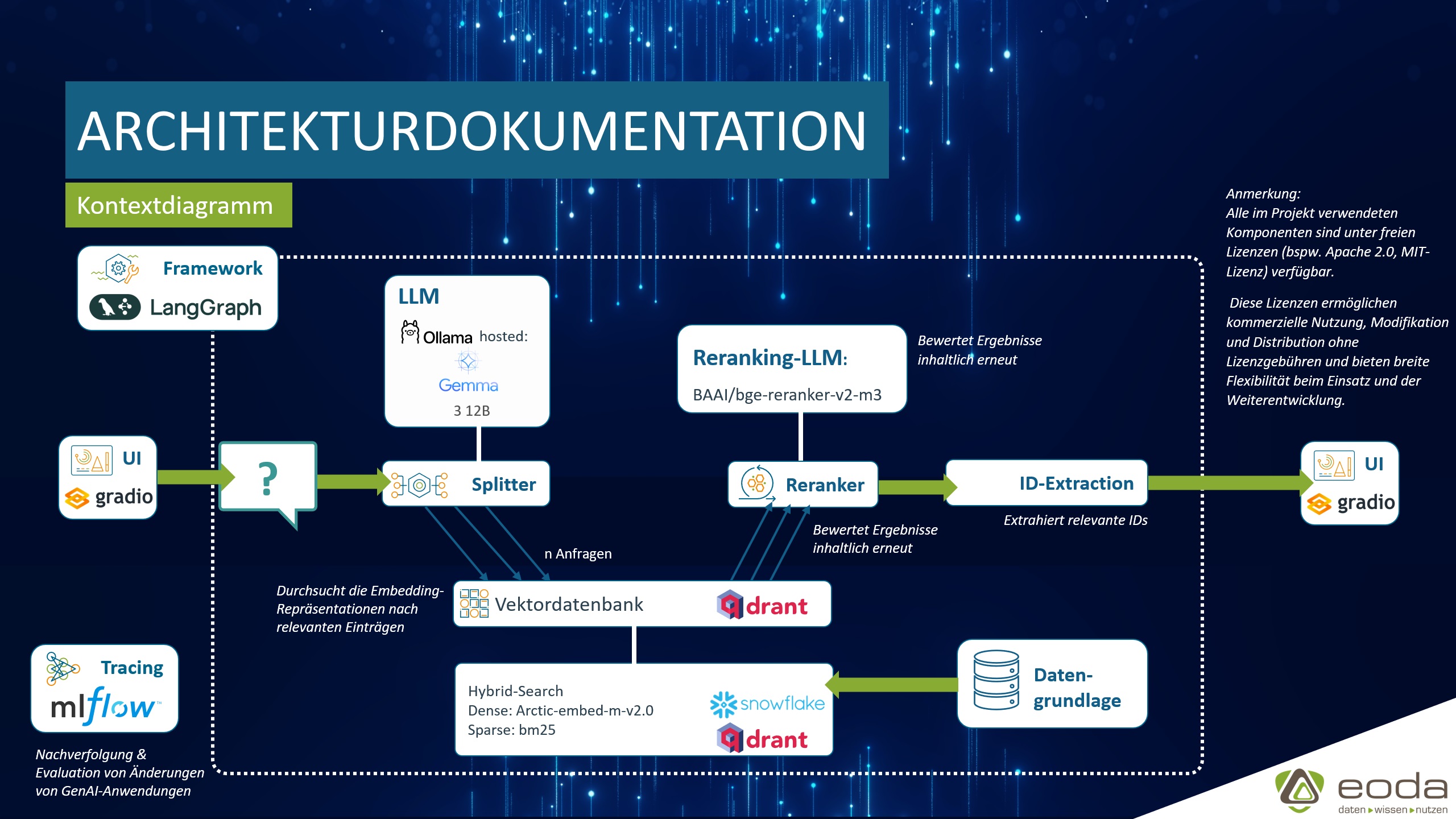
Die finalen Bausteine des Assistenzsystems
Das RAG-basierte Assistenzsystem besteht aus mehreren Kernkomponenten, die nahtlos ineinandergreifen:
- Splitter: Zerlegt Suchbegriffe, um bessere Treffer zu erzielen.
- Hybride Suche: Kombiniert Vektorsuche mit Volltextsuche für präzisere Ergebnisse.
- Embedding-Modell: Übersetzt Texte in numerische Vektoren, um semantische Ähnlichkeiten zu erfassen.
- Reranking: Ordnet die Suchergebnisse nach Relevanz für den Prüfprozess an.
- Vektordatenbank, befüllt mit der Datengrundlage.
- UI
Als zentrales Framework zur Orchestrierung LLM-basierter Workflows setzt eoda aufgrund der Flexibilität, Produktionsreife und aktiven Community auf Langgraph. Zur Evaluation der Optimierungsansätze sowie für Detailanalysen des LLM-Outputs setzen wir auf die etablierte Trackingbibliothek MLflow. Als initialer Schritt die Vektordatenbank mit den Dokumenten befüllt.
Der Splitter und das Reranking-Modell stellen Use-Case spezifische Bausteine dar, welche die klassische RAG-Architektur erweitern. Dadurch wird die Suche relevanter und effizienter gestaltet, was den Prüfprozess für die Mitarbeitenden deutlich erleichtert.
Aufbau einen RAG-Pipeline
Welche Aufgabe hat eine Vektordatenbank? Was ist ein Embedding-Modell? Eine Erklärung zu Bausteinen einer RAG-Pipeline finden Sie in unserem Blogbeitrag
Die RAG-Komponenten im Detail
Vektordatenbank & hybride Suche
Bei der initialen Iteration wurde ChromaDB verwendet. Im Laufe des Projekts zeigte sich, dass sich durch die Kombination von Qdrant und Snowflake Arctic Embed v2.0 die besten Ergebnisse in der lokalen Umgebung erzielen lassen, da Qdrant hybride Suchmöglichkeiten nativ unterstützt und sich durch eine gute Skalierbarkeit auszeichnet. Derartige Änderungen von Kernkomponenten sind mit Langgraph gut umsetzbar.
Die hybride Suche kombiniert Snowflake Arctic Embed v2.0 mit einer Art Volltextsuche. Letztere ist im Markenschutz besonders wichtig, da exakte Wörter oder Wortbestandteile entscheidend sein können. Bei der Modellwahl berücksichtigte eoda neben der allgemeinen Leistung auch die spezifischen Anforderungen des Anwendungsfalls: Mehrsprachigkeit, große Kontextlänge und kleine Modellgröße.
Snowflake Arctic Embed v2.0 erzeugt „dense“ Vektoren, die semantische Ähnlichkeiten abbilden. Das gewählte Modell ist mehrsprachig, sodass Texte in allen Landessprachen der Schweiz ohne Übersetzung verarbeitet werden können. Für die Extraktion direkter Worthäufigkeiten wurde für jeden Text ein zweiter „sparse“ Vektor mittels des bm25-Algorithmus erstellt. Da die meisten Texte kurz sind (1–2 Sätze bis 1 Seite), konnten sie dank der großen Kontextlänge ohne Chunking verarbeitet werden.
Beim Retrieval (dem Abruf von Informationen) werden für jede Suchanfrage sowohl ein „Dense“- als auch ein „Sparse“-Vektor generiert. Die eigentliche Suche ist dann ein Ähnlichkeitsvergleich zwischen diesen Anfragevektoren und den bereits in der Datenbank gespeicherten Einträgen. Das Ergebnis der Vektorsuche ist eine Liste von Dokumenten, die als „relevant“ eingestuft werden. „Relevant“ bedeutet hier, dass die Vektorrepräsentation der Anfrage eine hohe Ähnlichkeit zu den Vektorrepräsentationen der Suchergebnisse aufweist.
Beim Befüllen der Vektordatenbank speichern wir auch wichtige Metadaten ab, wie zum Beispiel die ID, die Nizza-Klassen und die Quelle des Dokuments. Diese Metadaten sind besonders wichtig für die spätere Extraktion der IDs am Ende des LLM-Workflows.
Splitter
Zur besseren Prüfung der Suchbegriffe werden diese aufgeteilt. Beispielsweise wird bei „eodaLAB“ sowohl „eodaLAB“ als auch „eoda“ und „LAB“ als Input für die nachfolgende Vektorsuche verwendet. Diese Komponente steigert den Recall deutlich.
Für den Splitter hat eoda verschiedene Sprachmodelle getestet (Gemma3, Deepseek-R1 und Qwen3). Dabei lieferte Gemma 3, welches über Ollama betrieben wird, die besten Ergebnisse. Es gehört zu den derzeit leistungsfähigsten Sprachmodellen, die auf einer einzelnen Grafikkarte „On-Premise“ betrieben werden können. Im Projekt wurde eine Gemma3-Version mit 12 Milliarden Parametern (12B) und Quantisierung gewählt.
Reranking & ID Extraction
Nach dem initialen Abruf passender Dokumente zur zu schützenden Marke aus der Vektordatenbank – sowohl für den Begriff als auch dessen Bestandteile – erfolgt eine Relevanzbewertung und Neuordnung der Treffer. Dafür wird das Reranking-Modell BAAI/bge-reranker-v2-m3 eingesetzt.
Das Modell wurde verwendet, weil es speziell für das Reranking optimiert wurde. Dieses vergleichsweise kleine Modell zeichnet sich durch seinen geringen RAM-Verbrauch und die sehr schnelle Ausführung aus und erzielt dabei sehr gute Ergebnisse.
Vorteil dieses Modells gegenüber allgemeinen LLMs wie Gemma3:
Das Modell ist genau für diese Funktion (Reranking) optimiert und liefert dadurch deutlich präzisere und schnellere Ergebnisse.
Die Ergebnisse des Rerankings enthalten Metadaten, insbesondere die ID des jeweiligen Eintrags. Diese IDs werden extrahiert und als finale Antwort zurückgegeben. Der Prozess ist deterministisch und benötigt kein zusätzliches LLM.
UI
Die Benutzeroberfläche wurde mit Gradio realisiert. Gradio ermöglicht einen schnellen Entwicklungszyklus und eignet sich gut für PoCs mit LLM-Komponenten. Die UI ermöglicht die Eingabe eines Suchbegriffs und zeigt die gefundenen, relevanten Einträge inklusive ihrer IDs an. Zusätzlich wird über die IDs eine Verlinkung in das IGE-Prüfungshilfesystem ermöglicht, sodass der Text der ausgewählten IDs direkt angezeigt werden kann.
Fazit
Das entwickelte RAG-basierte Assistenzsystem zeigt deutlich, wie Künstliche Intelligenz eingesetzt werden kann, um die menschliche Expertise in komplexen Anwendungsfällen, wie der Markenprüfung, zu bereichern. Durch die Integration moderner Methoden wie hybrider Suche und intelligentem Reranking wird die Markenprüfung in Zukunft spürbar effizienter. Dieses Projekt zeigt das enorme Potenzial von KI als wertvolles Werkzeug, das Fachpersonen bei ihrer täglichen Arbeit entlastet und ihnen ermöglicht, sich auf die kritischen Aspekte ihrer Arbeit zu konzentrieren.
Autoren
Matthias Henneke – Data Scientist
Christian Schreiner – Projektmanagement

Case Study: Wie kann die Zukunft der Markenprüfung mithilfe von KI und LLMs aussehen?
Erfahren Sie, wie wir das Eidgenössische Institut für Geistiges Eigentum (IGE | IPI) in Bern unterstützt haben, Künstliche Intelligenz einzusetzen.

Hintergrund: Aufbau einer RAG-Pipeline
Welche Aufgabe hat eine Vektordatenbank? Was ist ein Embedding-Modell? Eine Erklärung zu Bausteinen einer RAG-Pipeline finden Sie in unserem Blogbeitrag

Entwicklung Verbinden Sie GenAI mit Ihrem Unternehmenswissen
Wir entwickeln Ihre Generative-AI-Lösung mit RAG-Funktionalität von der Konzeption über die Datenanbindung bis hin zur Implementierung und dem sicheren Betrieb.

Blog: LLM basierte Agenten-Systeme: Intelligente Assistenten für automatisierte Prozesse
Agenten-Systeme basieren auf der Kombination verschiedener Komponenten, die zusammenarbeiten, um komplexe Probleme zu lösen. Doch was zeichnet diese Systeme aus und wie funktionieren sie? In diesem Blogartikel geben wir einen Einblick