Zeitungsartikel, E-Mails, Briefe – Texte begegnen uns täglich auf unterschiedlichen Wegen. Unabhängig von der Übermittlungsart, der Länge und der Thematik eint die Verfasser das Bestreben nach einer hohen Verständlichkeit. Produktinformationen im Marketing, wissenschaftliche Ausarbeitungen, journalistische Artikel – die konkreten Beispiele, in denen eine hohe Verständlichkeit von niedergeschriebenen Inhalten wichtig ist, sind vielfältig. Eine verständliche Ausdrucksweise ist der Grundstein für nachvollziehbare Texte.
Dennoch begegnen einem im Alltag immer wieder Texte, bei denen es schwer fällt, sich den darin enthaltenen Inhalt zu erschließen. Neben für den Verfasser nicht beeinflussbaren Faktoren wie Fachwissen und Interesse des Rezipienten ist häufig eine unzureichende Lesbarkeit der Grund dafür, dass Botschaften falsch oder teilweise gar nicht beim Empfänger ankommen. In vielen Fällen ist die Komplexität vieler Texte nicht angemessen für die angesprochene Zielgruppe. Um dies zu erkennen und zu verbessern bietet sich die Anwendung des Flesch-Indexes unter zur Hilfename von Text Mining an.
Der Flesch-Index als Kriterium für die Lesbarkeit
Neben der Leserlichkeit, der inhaltlichen Struktur und dem Aufbau eines Textes ist die Lesbarkeit eines der Kriterien für die Textverständlichkeit. Die Lesbarkeit beschreibt die sprachliche Gestaltung. Hierzu zählen beispielsweise der Wortschatz oder die Komplexität der verwendeten Wörter und Sätze.
Der US-amerikanische Autor Rudolf Flesch entwickelte den nach Ihm benannten Flesch-Index. Dieser umfasst ein Verfahren zur formalen Bestimmung der Lesbarkeit eines Textes. Dieses ermöglicht es, Texte zu überprüfen und eine präzise Aussage darüber zu erhalten wie hoch die Lesbarkeit ist. Verfasser haben so die Möglichkeit einer Selbstkontrolle und erhalten Ansatzpunkte für Optimierungen. Zudem lassen sich Texte anhand der Bewertung durch den Flesch-Index klassifizieren. Da die Wortlänge in der deutschen Sprache im Durchschnitt höher ist als im Englischen, wurde der Flesch-Index von Toni Amstad an die deutsche Sprache angepasst.

Berechnungsformel des Flesch-Index für die englische SpracheBei dem Ergebnis des Flesch-Index unterscheidet man allgemein zwischen einem hohen und niedrigen Komplexitätsgrad, wobei dieser mit steigendendem Wert abnimmt. Ein Text mit einem hohen Flesch-Index wie 100 würde demnach aus Sätzen bestehen, die jeweils lediglich zwei einsilbige Wörter enthalten und entspräche so einem niedrigen Komplexitätsgrad. Texte mit einem Flesch-Index von 20 und geringer sind entsprechend komplexer aufgebaut und entsprechen beispielsweise einer wissenschaftlichen Veröffentlichung, die sich in der Regel durch vielsilbige Fachbegriffe und komplexe Satzstrukturen auszeichnet.
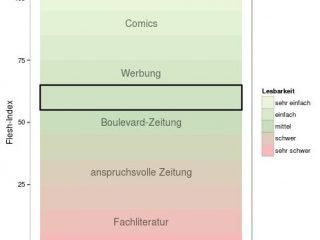


Texte einer gewöhnlichen Tageszeitung erzielen in der Regel Werte zwischen 30 und 50. Dies bestätigt die beispielhafte Analyse von Artikeln aus großen deutschen Tageszeitungen zu den olympischen Winterspielen 2014 in Sotschi.
Flesch-Index als neues Feature für die webbasierte Anwendung „textmineR“ auf der eoda Serviceplattform
Hier entlang.