Eingerahmt von den beiden Keynotes von Deborah Nolan und Simon Urbanek bot auch der abschließende Tag der useR! 2016 interessante Talks, auf die wir im Folgenden eingehen.
Alex Cozzi: Gradient Boosted Trees Model: deploying R models into production environments
Alex Cozzi hat den useR! Teilnehmern erläutert, wie R bei eBay verwendet wird: Bei jeder Suchanfrage wird im Hintergrund ein Gradient Boosting Modell (GBM) ausgeführt. Aufgrund zahlreicher Vorteile, ist dieses Verfahren das derzeit beliebteste bei eBay:
- State of the Art Performance
- Die Variablen/Features müssen nicht metrisch sein
- Die Modelle entdecken auch nicht-lineare Zusammenhänge
- GBM ist relativ robust gegen overfitting
- Mit Variable Importance- und Dependency-Plots lässt sich die Bedeutung der eingegangenen Variablen bestimmen. GBMs können somit nicht nur zur Prognose, sondern auch zur Erklärung herangezogen werden.
eBay verfügt erwartungsgemäß über einen enormen Datenpool, verwendet davon aber nur einen vergleichsweise geringen Anteil für die Analyse. Aus Cozzis Sicht ist es wichtig Zugang zu großen Datenmengen zu haben. Es ist jedoch weniger wichtig, diese Daten tatsächlich vollständig zu verwenden. Denn Daten sind nie vollständig. Es gibt immer Informationen, die nicht vorliegen. Ohnehin sind schnelle Ergebnisse höher zu bewerten als die Vollständigkeit der Daten.
Das Anwendungsszenario für R ist vor allem die explorative Analyse sowie das Prototyping. Die Data Scientists bei eBay schätzen an R, dass
- man schnell zu Ergebnissen kommt
- sich viele unterschiedliche Ideen ausprobieren lassen
- Ergebnisse gut visualisiert werden können
- Prototypen schnell erstellt werden können.
Das Training und die Validierung der Modelle führt eBay mit R durch. Die Modellanwendung im Produktionsbetrieb wird dagegen derzeit noch nicht mit R umgesetzt. Stattdessen werden die Modelle mit Hilfe eines selbst entwickelten JSON Formats exportiert. Dieses orientiert sich an PMML, ist aber flexibler und gleichzeitig kompakter. Produktiv werden die Modelle dann mit C++ bzw. Java implementiert.

Marvin N. Wright: ranger – A fast implementation of random forests for high dimensional data
Marvin N. Wright von der Universität zu Lübeck hat das Paket „ranger“ vorgestellt. ranger ist eine Reimplementierung von Random Forest, das auch bei hochdimensionalen Daten (d.h. Datensätzen mit vielen Features) sehr gut performt. Im Vergleich zur klassischen Random Forest Implementierung im „randomForest“ Paket ist ranger bis zu 200-fach schneller und verbraucht dabei zum Teil nur ein Fünftel des Arbeitsspeichers. Von der Modellperformance ist ranger mit random forest vergleichbar. Die Analyseergebnisse wurden von den Paketentwicklern mit random forest validiert.
Ranger bringt darüber hinaus einige zusätzliche Features mit:
- Es können Survival-Trees gerechnet werden
- Wahrscheinlichkeiten für Mehrklassenvariablen geschätzt werden
- GWAS-Daten (Genomweite Assoziationsstudie) können bearbeitet werden
Rebecca Louisa Barter: superheat – Supervised heatmaps for visualizing complex data
Rebecca Barter hat in ihrer Präsentation das Paket „superheat“ vorgestellt. Mit superheat können headmaps erstellt werden. Zwar gibt es bereits einige Pakete, mit denen sich heatmaps zeichnen lassen, z.B. geom_raster in ggplot2, heatmap, heatmap2 oder d3heatmap. superheat bringt jedoch einige interessante Features mit, die in den anderen Paketen nicht zu finden sind.
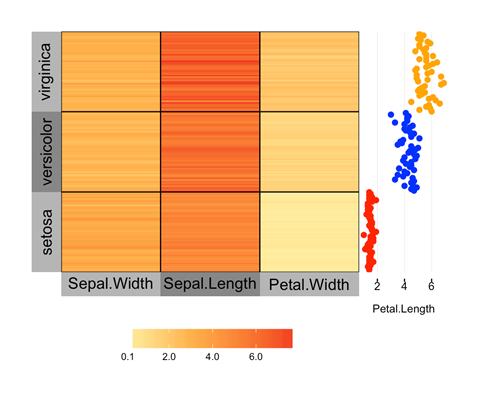
So können Clusterinformationen in die Heatmaps integriert werden. Das ist insbesondere dann sinnvoll, wenn die zu plottenden Variablen viele Ausprägungen haben. Die Clusterinformationen lassen sich entweder on-the-fly mit k-means berechnen, manuell einfügen oder mit einem beliebigen externen Clusteralgorithmus berechnen.
An die x- und y-Achse können weitere Variablen zur Verdeutlichung angefügt werden. Auch Texte können an die heatmaps angefügt werden.

Lightning Talks
Nathan Pavlovic: Interactive dashboards for visual quality control of air quality data
Nathan Pavlovic widmete sich dem Thema der Messung von Luftqualität. Klassisch wird Luftgüte mit hochwertigen Messgeräten erfasst, die von Behörden (z.B. dem Bundesumweltamt oder den Städten und Gemeinden) aufgestellt werden. Daneben gibt es mittlerweile eine Vielzahl von kleinen Geräten zur Messung der Luftreinheit. Diese werden beispielsweise von Asthmatikern oder Allergikern verwendet. Die Daten, die von diesen Geräten erfasst werden, können über Internetportale hochgeladen werden, so dass sich durch diese ungesteuerten und dezentralen Messungen die Messdichte und der kartierte Bereich deutlich vergrößert.
Die Datenqualität der von Privatpersonen bereitgestellten Messergebnisse ist allerdings nicht immer zufriedenstellend. Nathan Pavlovic hat in seinem Vortrag dargelegt, wie man mit einer Shiny-App Messdaten manuell überprüfen kann und so die Datenqualität signifikant erhöht.
Gabrielle Jeanne Weinrott: Visualization of Uncertainty for Longitudinal Data
Gabrielle Weinrott vom INRA Montpellier hat in ihrem Lightningtalk vorgestellt, wie sich mit Bayes Statistik latente Klassen analysieren und visualisieren lassen.

Raphaël Nedellec: Scalable semi-parametric regression with mgcv package and bam procedure
Raphaël Nedellec hat vorgestellt wie semi-parametrische Regressionsmodelle auch auf großen Datensätzen performant berechnet werden können. Hierfür verwendet er das Paket BaM („Big Gerneralized Additive Models“), eine besser skalierende Erweiterung von gam („Gerneralized Additive Models“).
Dean Attali: shinyjs: Easily improve UX in your Shiny apps without having to learn JavaScript
Das Paket „shinyjs“ war Thema des Vortrags von Dean Attali, wissenschaftlicher Mitarbeiter an der University of British Columbia. shinyjs erweitert shiny um einige hilfreiche Zusatzfunktionen. So lassen sich interaktive Shiny-Apps für die User leichter nutzbar machen. Grafikelemente können ein- und ausgeblendet und es kann zwischen verschiedenen Elementen umgeschaltet werden. Auch das aktivieren bzw. deaktivieren von Elementen lässt sich mit shinyjs steuern. Ein weiteres Feature ist ein Colorpicker, mit dem auf dem Bildschirm dargestellte Farben aufgegriffen und in die Visualisierungen eingebaut werden können.
Stefan Feuerriegel: Understanding human behavior for applications in finance and social sciences: Insights from content analysis with novel Bayesian learning in R
Stefan Feuerriegels Beitrag hatte Pakete zur Sentimentanalyse zum Thema. Sein Ansatz basiert zunächst auf Dictionaries. Diese können extern angefügt, aber auch als Teil der Analyse auf empirischer Basis generiert werden.
Die Sentimentanalyse wird mit Hilfe von Bayesscher Statistik umgesetzt. Auf dieser Basis lassen sich verschiedene Kennwerte und Elemente extrahieren:
- Die Stimmung des Textes (positiv oder negativ)
- Textuelle Einflussfaktoren
- Über- und Unterrepräsentation von Begriffen in positiven bzw. negativen Texten
- Die Position von sentimenttragenden Begriffen innerhalb des Textes.
Anwendungsfälle finden sich im Finanzbereich und in der Sozialforschung. Darüber hinaus lassen sich leicht weitere Anwendungsfelder vorstellen.

Hier entlang.