RStudio Chief Scientist Hadley Wickham hat mit seiner mit Spannung erwarteten Keynote Tag 3 der useR! Conference 2016 eingeleitet.

Hadley Wickham: Einer der Keynote Speaker der useR! 2016
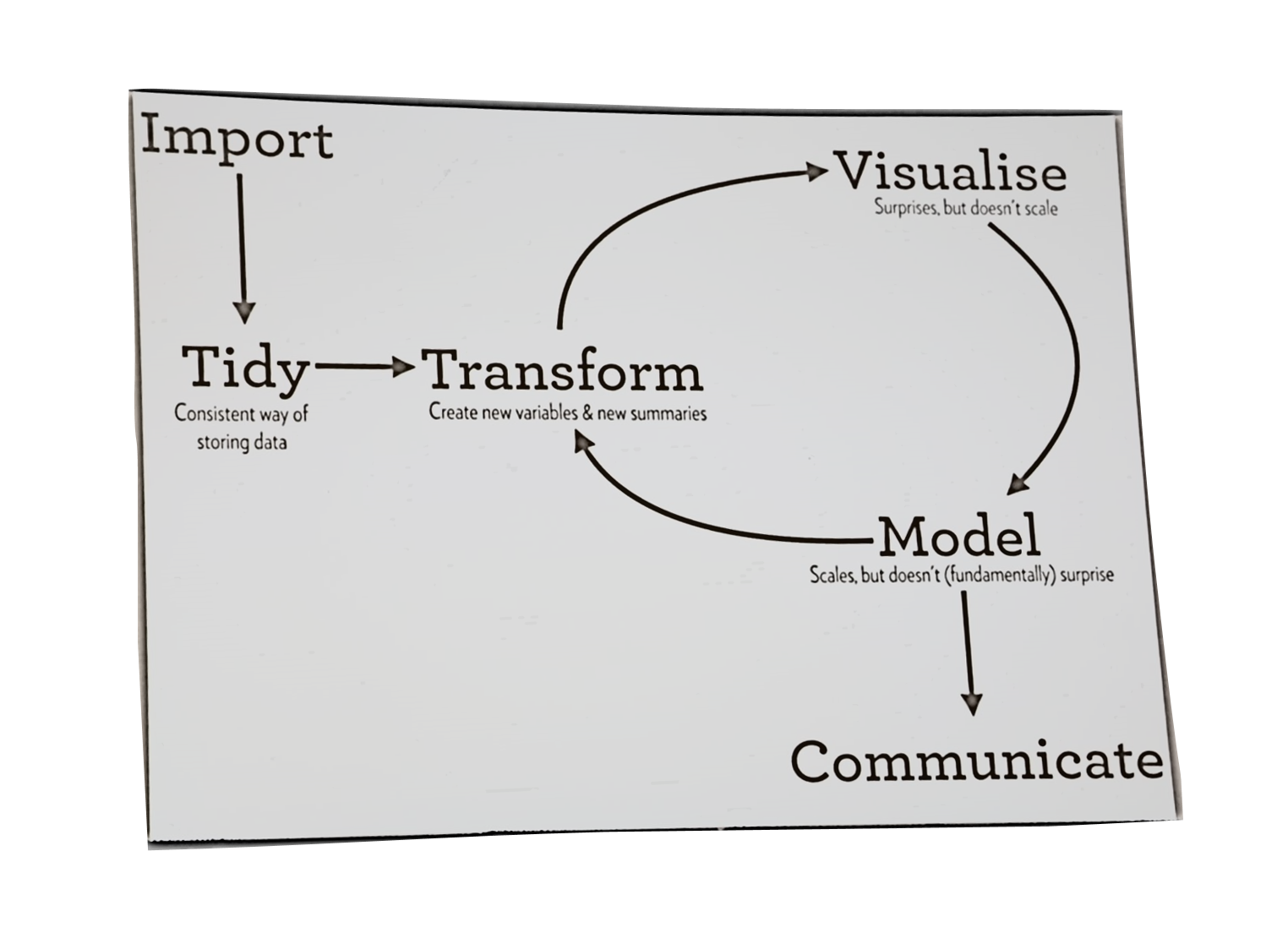
In seinem Vortrag hat Hadley Wickham zunächst den typischen Data Science Workflow mit folgenden Schritten beschrieben:
- Import: Import der Daten in R.
- Tidy: Konsistente Speicherung der Daten: Vereinheitlichung, Labeling, Behandlung fehlender Werte, Umformen in die richtigen Klassen (factor/character) etc.
- Transformation: Damit ist Feature Engineering gemeint: Berechnung neuer Variablen, z-Transformationen, Rekodierungen etc.
- Visualisierung: Graphische Aufbereitung der Daten
- Modellierung: Erstellen von Data Mining Modellen
- Kommunikation: Zum Beispiel mit dem Fachbereich oder anderen Abteilungen
Anschließend hat Wickham seine Idee des „tidyverse“ vorgestellt. Ein einheitliches Framework für Datenanalyse. Die „tidyness“ bezieht sich dabei zum einen auf die Datenstrukturen, zum anderen auf die Tools, die zur Analyse verwendet werden.
Tidy Data
Daten sind „tidy“ wenn die Datenstrukturen einheitlich sind. Wickham schlägt dafür folgende einfache Regeln vor:
- Daten werden in data.frames abgelegt
- Variablen sind in Spalten
- Wenn ein data.frame keinen Sinn macht, sollte die verwendete Struktur konsistent sein.
In einem typischen Analyse Workflow liegen Daten häufig in verschiedenen Formaten vor: Training Daten als data.frame, Test Daten ebenfalls als data.frame, ein Prognosemodell als Liste, die Prognosewerte als Vektor.
Ein Lösungsansatz um mehr Konsistenz in die Heterogenität zu bekommen bietet das „tibble “ Paket. Ein „tibble “ ist eine Variante des data.frame Objekttyps. Es wird mit der data_frame bzw. as_data_frame Funktion erstellt. Die Syntax ähnelt somit sehr der des original data.frames.
Ein Tibble unterscheidet sich durch folgende Eigenschaften von einem data.frame:
- In den Spalten können auch Listen aufgenommen werden, nicht nur Vektoren
- Kein „partial matching“
- In der Ausgabe werden die Klassen der Spalten angegeben und lediglich die ersten zehn Zeilen angezeigt
Das die Spalten eines Dataframes Listen enthalten können ist neu, obwohl naheliegend: Schließlich ist ein data.frame eine Liste von Vektoren gleicher Länge. Die Möglichkeit Listen aufnehmen zu können ist notwendig, wenn erreicht werden soll, dass praktisch alle Daten in einer data.frame artigen Struktur abgelegt werden soll.
Ein Anwendungsfall für ein Tibble ist die Visualisierung von Geodaten: Geodaten sind Listen, die die Daten enthalten, die notwendig sind, um ein Polygon zu zeichnen – zum Beispiel den Umriss eines Landes. Darüber hinaus enthalten Geodaten häufig einen data.frame, der Metainformationen zu den Regionen enthält. Diese Metadaten sind im Vergleich zu den Polygon-Daten deutlich kleiner. Wenn beim Zeichnen mit ggplot Labelinformationen verwendet werden sollen, müssen die Metadaten an die Polygondaten angespielt und somit repliziert werden. Dies ist nicht sehr effizient ist. Mit Tibbles könnten die Daten zusammengeführt werden ohne sie zu replizieren.
Tidy Tools
Tools, also APIs und Funktionen, sind tidy, wenn sie folgende Bedingungen erfüllen:
- Jede Funktion erfüllt genau eine Aufgabe
- Einfache Schritte werden mit Pips (%>%) zusammengefügt
- Funktionen sollten referentiell transparent sein: Die Rückgabewerte hängen nur von den Eingabewerten ab und die Funktion nimmt keinerlei Veränderungen außerhalb der Funktion vor.
Das Ziel von tidy tools ist es, komplexe Probleme durch die Verkettung einfacher Bestandteile zu lösen. Plastisches Beispiel ist der Aufbau der physischen Welt: Eine Funktion ist ein Atom: Sie erledigt genau eine Aufgabe. Mehrere Funktionen werden per Pipe zu Molekülen verkettet. Und aus Molekülen können komplexe Strukturen gebaut werden.
Nutzen Sie unsere maßgeschneiderten Lösungen in Data Science und IT-Sicherheit, um Ihre Systeme zu optimieren und Risiken zu minimieren.
Author
Starten Sie jetzt durch:
Wir freuen uns auf den Austausch mit Ihnen.