
Wie sich Shiny® und YUNA gegenseitig ergänzen
Lesezeit: ca. 4 min
Neben einer strukturierten Aufbereitung und Organisation von Daten und Analyseergebnissen sind Flexibilität und Dynamik im Bereich Data Science enorm wichtig. Um Erkenntnisse aus Daten zu gewinnen, müssen sie oftmals zunächst explorativ untersucht werden. Im Idealfall ist die Barriere, um Daten visualisieren und explorativ erkunden zu können, für den Data Scientist relativ gering. Ebenso sollten Daten und Analyseergebnisse für Fachanwender sowie Manager in einer ansprechenden und bestenfalls interaktiven Form dargestellt werden, welche möglichst geringen Aufwand für den Data Scientist bedeuten. Ein geeignetes Format ist zum Beispiel eine Shiny®-Anwendung, die der Data Scientist eigenständig und ohne große Hürden entwickeln kann. Durch das neue Integrationswidget, kann diese Shiny-Anwendung problemlos in YUNA-Dashboards integriert und anderen Nutzern zur Verfügung gestellt werden. Damit trifft die Skalierbarkeit und administrative Struktur (Rollen- & Rechtekonzept) von YUNA auf die Flexibilität und Interaktivität von Shiny.
Shiny Apps für interaktive Grafiken und Ad-hoc-Analyse
Shiny ist ein R-Paket zur Entwicklung von Web-Anwendungen. Die intuitive Entwicklung und die große Anzahl an Konfigurations- und Darstellungsmöglichkeiten ermöglichen es, Daten interaktiv aufzubereiten und parametrisierbare Ad-hoc-Analysen durchzuführen. So kann eine Shiny-App ähnlich wie statische Grafiken, Tabellen oder Reports als eine Form der Ergebnisdarstellung genutzt werden.
Der Vorteil: Der Data Scientist kann die Web-Anwendung in der gleichen Sprache – R – entwickeln, wie die Analyse selbst. Somit können Anwendung bzw. Darstellungsform und Analyse vollständig vom Data Scientist aufeinander abgestimmt werden. Ein zentraler Aspekt bei der Nutzung von Shiny-Apps als Darstellungsform von Ergebnissen, ist die Möglichkeit interaktive Grafiken einzubinden, um vorliegende Daten oder Analyseergebnisse explorativ zu untersuchen. Auch hier spielt der Aspekt der Programmiersprache eine Rolle. Da die Shiny-App in R geschrieben wird, muss der Data Scientist sich keine Gedanken um Datenmodelle oder Widget-Definitionen machen. Ein weiterer Aspekt ist die Möglichkeit, den User durch verschiedene Input-Möglichkeiten (Schieberegler, Multiple-Choice-Selektion, …) Parameter definieren zu lassen. Diese können beispielsweise Tabellen filtern oder den Wertebereich von Grafiken einschränken, um Ergebnisse zu filtern oder auf Besonderheiten einzuschränken bevor man sie exportiert und mit anderen Nutzern teilt. Neben der interaktiven Darstellung von Ergebnissen und der Parametrisierbarkeit dieser Darstellung, lassen sich in Shiny-Applikationen auch mit R entwickelte Ad-hoc-Analysen (z.B. Zeitreihenprognosen) integrieren. Auf die gleiche Art und Weise können Daten eingeschränkt werden, um auf dieser Datengrundlage ein Machine-Learning-Modell zu berechnen. Die Ergebnisse werden wiederum unmittelbar nach der Berechnung in der Shiny-Applikation dargestellt und können direkt evaluiert werden. Damit die reibungslose Zusammenarbeit funktioniert, benötigt es weiterhin einen RStudio Connect bzw. RStudio Shiny Server Pro.
Shiny trifft YUNA
Durch das Integrieren einer Shiny-Applikation in YUNA können die interaktiven und flexiblen Elemente von Shiny als zusätzliche Darstellungsmöglichkeit innerhalb eines YUNA Dashboards genutzt werden.
Auf der anderen Seite können YUNA Features wie das Rechte-und-Rollen-Konzept sowie frei konfigurier- und teilbare Filter innerhalb der Shiny-App zum Einsatz kommen. Zusätzlich kann über die in YUNA vergebenen Rollen gesteuert werden, welche Nutzer die Applikation bzw. das für die Applikation gebaute Dashboard sehen bzw. nutzen können. Außerdem kann die Rolle an die Shiny-Applikation weitergereicht werden. Innerhalb der Shiny-App können abhängig von der Rolle zum Beispiel nur ausgewählte Daten und Ergebnisse dargestellt oder bestimmte interaktive oder Ad-hoc-Analyse blockiert werden.
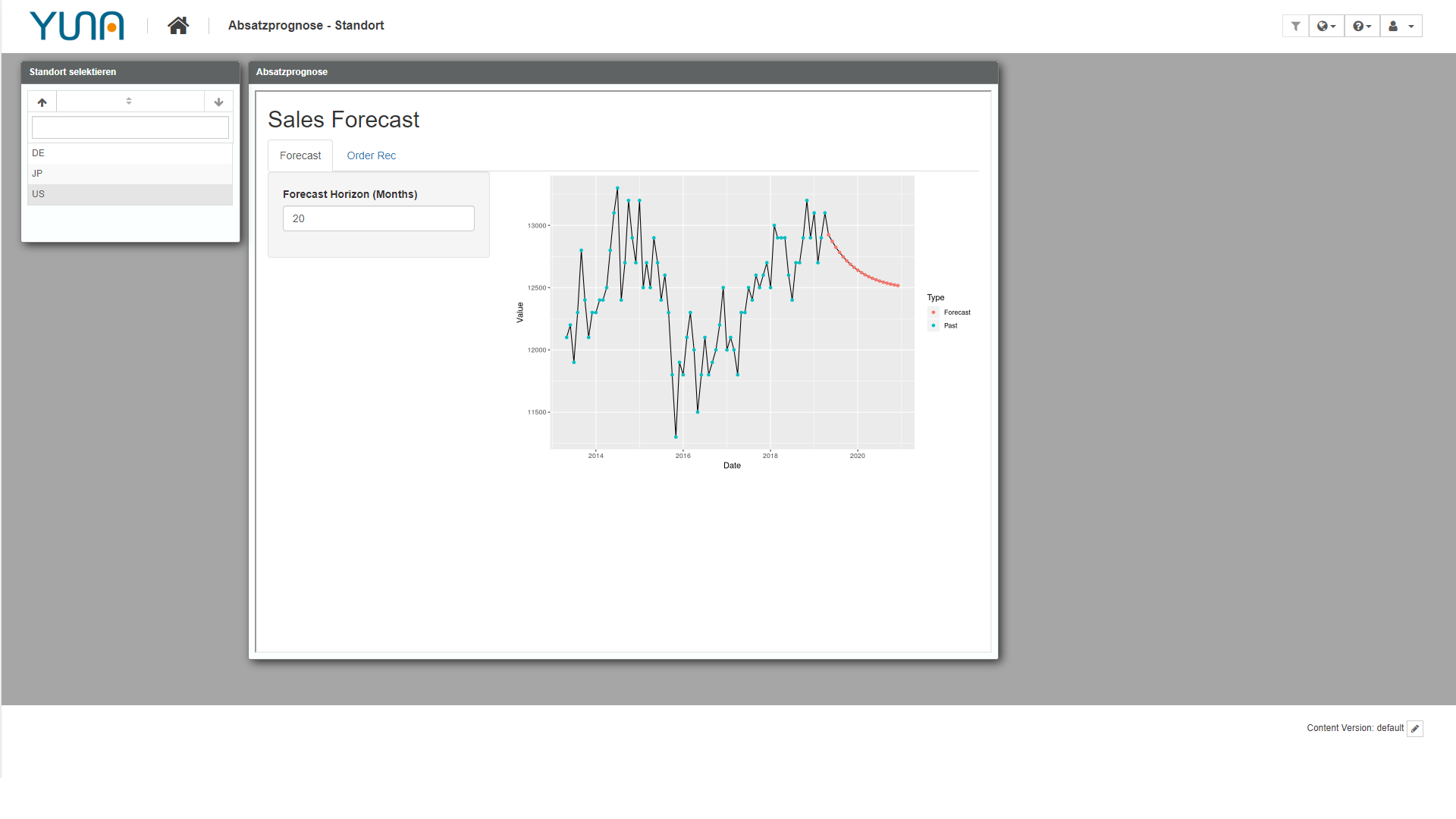
Integrierte Shiny-App zur Darstellung eines Sales-Forecasts
Weiterhin besteht die Möglichkeit in YUNA definierte Parameter und Filter an die Shiny-App weiterzugeben, um von Anfang an die Datengrundlage entsprechend des Filters einzuschränken oder bestimmte Metaparameter für Ad-hoc-Analysen oder Grafiken zu definieren. Der Filter wird automatisch bei der Datenabfrage angewendet, sodass in der Shiny-App die dem Filter entsprechenden Daten zur Verfügung stehen. Die in YUNA definierten Parameter können beispielsweise als Analyseparameter genutzt werden (z.B. zeitlicher Horizont bei der Prognose von Zeitreihendaten) oder verwendet werden, um Grafiken zu konfigurieren (bspw. das Anzeigen von Daten für einen bestimmten definierten Standort). Die Konfiguration einer Shiny-App mittels YUNA ermöglicht die Einbindung der gleichen Shiny-Applikation in verschiedene Dashboards mit unterschiedlichen Konfigurationsmöglichkeiten und Filtern.
Integrationswidget in der Praxis
Betrachten wir den Use Case einer Absatzprognose für verschiedene Produkte an verschiedenen Standorten:
Der Data Scientist erstellt ein einfaches Baseline-Modell, um die Absatzzahlen zu prognostizieren. Diese Analyse implementiert der Data Scientist als Shiny-Anwendung, die die historischen Absatzzahlen und die Prognose für einen durch den Nutzer konfigurierbaren Zeithorizont darstellt. Diese Shiny-Anwendung lässt sich über das Integrationswidget in ein YUNA-Dashboard integrieren, auf der die Nutzer die Absatzzahlen für ihren jeweiligen Standort sehen. Dabei geschieht die Filterung der Daten (Standort, Produktkategorie etc.) automatisch in Abhängigkeit der Rolle des Nutzers und wird in der Shiny-App angewendet, um lediglich die eingeschränkten Daten anzuzeigen. Die Shiny-App kann vom Nutzer dann benutzt werden, um für einen gewünschten Zeithorizont eine Prognose zu erzeugen und sowohl die historischen Absatzzahlen als auch die modellbasierte Prognose interaktiv zu explorieren.
Somit kann eine in Shiny integrierte Analyse von verschiedenen Nutzern für verschiedene Datengrundlagen genutzt werden. Dies bietet Flexibilität und eine interaktive Darstellungsmöglichkeit für die Endnutzer (z.B. Produktmanager am jeweiligen Standort). Die Arbeit des Data Scientists besteht aus der Entwicklung einer Analyse, welche von ihm in Shiny, dem ihm bekannten Tool, als Web-Anwendung implementiert und problemlos in YUNA integriert werden kann.
Zusammenfassung
Die Integration von Shiny in YUNA bietet viele Vorteile. Zum einen können Datenanalysten und Data Scientists schnell eigene Web-Anwendungen für ihre Analysen schreiben. Zum anderen können die Ergebnisse noch detaillierter und nutzerspezifischer ausgegeben werden, da die zuvor definierten Filter und Parameter aus YUNA heraus genutzt werden können. Gleichzeitig müssen keine dedizierten Shiny-Anwendungen für jede einzelne Nutzergruppe geschrieben werden, weil das Rechte- und Rollenkonzept aus YUNA genutzt wird. So können Analysen und deren Ergebnisse schneller geteilt und von noch mehr Menschen profitabel genutzt werden.
RStudio und Shiny sind Warenzeichen von RStudio, PBC