Öffentlich verfügbare Datensätze: Mit „Titanic“ auf der Suche nach der Wahrheit – musste Jack wirklich sterben?
Daten gelten als das Gold des 21. Jahrhunderts. Im Rahmen dieser Blogserie stellen wir besondere Datenschätze vor – frei verfügbar, thematisch interessant und für den Einsatz unterschiedlicher Analysen geeignet. Wir zeigen exemplarische Analysen des Datensatzes und geben Anregungen für weiterführende Untersuchungen. Zum Auftakt der Open-Data-Serie widmen wir uns einem der populärsten Datensätze.
In der Nacht vom 14. auf den 15. April 1912 sank die RMS Titanic auf ihrer Jungfernfahrt von Southampton nach New York. Aufgrund des gleichnamigen Spielfilmdramas (1997) ist das Unglück bis heute weltbekannt und gerade das weibliche Publikum ist immer wieder gefesselt von der Liebesgeschichte von Rose und Jack, die so tragisch mit dem Tod von Jack endet.
Noch mehr öffentlich verfügbare Datensätze
Wir haben noch weitere freie Datensätze identifiziert und stellen Sie in unseren Blog-Tutorials vor:
Mit VGChartz in das Reich der Videospiele eintauchen

Doch ist es vorhersehbar, dass Jack sterben und Rose das Unglück überleben wird?
Mit Data Mining lässt sich das herausfinden. Der Datensatz „Titanic“ ist im gleichnamigen Paket in R implementiert. Alternativ lässt sich der Datensatz hier herunterladen.
Dort ist er in einen Trainings- und einen Testdatensatz aufgeteilt und bietet die Möglichkeit, Modelle für den Trainingsdatensatz zu erstellen und durch diese Modelle Vorhersagen über das Überleben der Passagiere im Testdatensatz zu tätigen.
Der Trainingsdatensatz enthält 891 Beobachtungen mit 12 Variablen, der Testdatensatz 418 Beobachtungen mit 11 Variablen, da die kategoriale Zielvariable Survived (Überleben) nicht vorhanden ist.

Warum eignet sich der Datensatz für Data Mining?
Die Zielvariable ist das Überleben der Passagiere, welche eine kategoriale Variable ist. Somit handelt es sich um eine binäre Vorhersage, die die simpelste Form der Klassifikation darstellt. Außerdem ist der Datensatz bereits für den Data-Mining-Prozess vorbereitet, indem er in Test- und Trainingsdaten unterteilt wurde. Data Mining zielt darauf ab, aus bekannten Informationen ein Modell zu generieren und dieses auf neue Daten anzuwenden. Hier ist das Ziel eine Vorhersage über das Überleben der Personen im Testdatensatz, sowie das Überleben von Jack und Rose zu treffen.
Was wissen wir über Jack und Rose?
Da wir auch die Überlebenswahrscheinlichkeit für Jack und Rose vorhersagen wollen, müssen Informationen über ihren Aufenthalt auf der Titanic bekannt sein.

Da über Ticket, Fare und Cabin keine Informationen vorliegen, könnte man diese entweder durch Imputation auffüllen oder die drei Variablen für die Analyse ausschließen.
Der Data-Mining-Workflow
Im Data Mining durchläuft man zur Erstellung einer Prognose einen Prozess. Dieser Prozess wird hier beispielhaft erklärt und soll einen Leitfaden für weitere Prognosemodelle darstellen. Das Paket caret eignet sich zur Umsetzung in R, da es verschiedenste Funktionen zur Unterstützung des Data-Mining-Prozesses enthält.
Vor Beginn des Prozesses sollte ein erster Eindruck vom Datensatz gewonnen werden. Dies kann beispielsweise durch Visualisierung geschehen. Anschließend kann mit dem Workflow begonnen werden.
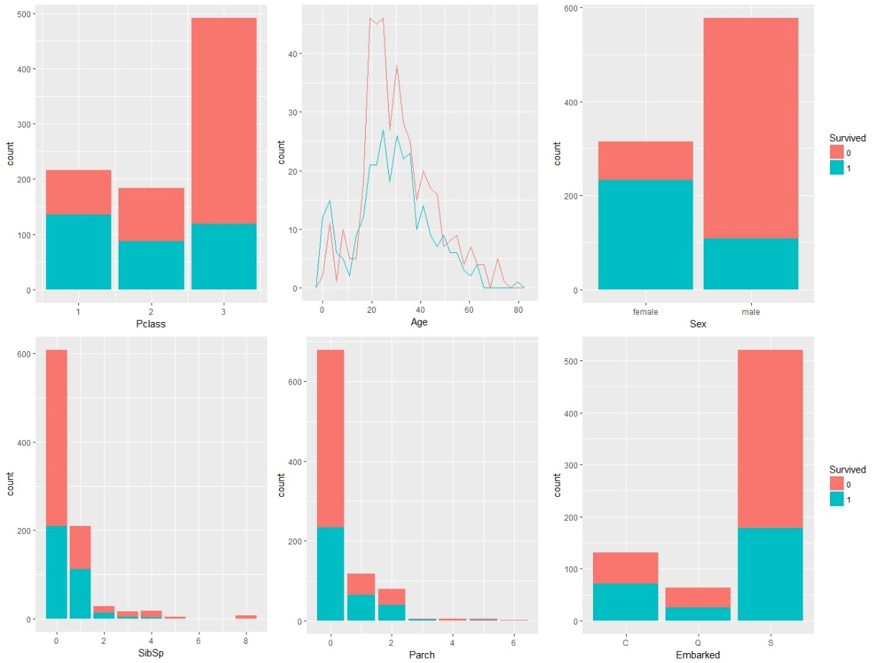
Das Datenmanagement
Im Datenmanagement werden die Datensätze unter anderem auf fehlende Werte und Korrelationen zwischen den einzelnen Variablen untersucht. Im Titanic Datensatz sollte man sich besonders mit der Missings-Imputation für die Variable Age (metrisch) beschäftigen. Die fehlenden Werte könnten zum Beispiel durch das k-Nearest Neighbor Verfahren oder durch Median-Werte ersetzt werden (im folgenden Modell wurden die NAs gelöscht).
Der Großteil der Datenunterteilung wurde bereits vorgenommen, dennoch muss noch ein Teil der Trainingsdaten in einen Validierungssatz unterteilt werden, an dem das Modell zuerst überprüft wird, bevor es auf den Testdaten angewendet wird. Es gibt verschiedene Sampling Methoden. Eine Möglichkeit wäre, mit der Funktion createDataPartition einen 80% (Trainingsdaten) / 20% (Validierungsdaten)-Split vorzunehmen.
Die Trainingsphase
In der Trainingsphase wird auf die Trainingsdaten ein geeignetes Modell angewendet. Da eine Klassifikation stattfinden soll, eignen sich als Modell z.B. Klassifikationsbäume, Neuronale Netze, Random Forest oder Gradient Boosting Machines. Das Ziel ist es, ein Modell mit möglichst guter Vorhersagekraft zu finden. Daher werden verschiedene Modelle ausprobiert und durch Benchmarks verglichen. Die folgende Prognose basiert auf einem GLMNet Modell, welches mit folgender Funktion berechnet wird:
glm <- train(Survived ~., titanic_train, method = „glmnet“, family = „binomial“).
Die Validierungsphase
In der Validierungsphase wird das berechnete Modell mit predict auf die Validierungsdaten angewendet. Als Bewertungskriterium kann z.B. die Accuracy (Genauigkeit) oder die Area under the (ROC)-Curve verwendet werden. Durch die Konfusionsmatrix (confusionMatrix) kann man erkennen, wie viele Fälle richtig vorhergesagt worden sind. Das oben genannte Modell weist eine Genauigkeit von 0,75 und eine AUC von 0,78 auf. Diese Werte lassen eine Verwendung dieses Modells zur Prognose der Testdaten zu.
Die Prognose
Wenn ein Modell gefunden wurde, welches eine zufriedenstellende Vorhersage für die Validierungsdaten aufweist, wird mit diesem Modell erneut mit der predict-Funktion eine Prognose der Variable Survival für die Testdaten erstellt. In der predict-Funktion lässt sich per type einstellen, ob die Prognose als Klassenzuordnung oder Wahrscheinlichkeit ausgegeben werden soll.
Die Interpretation
Die Interpretation wird auf inhaltlicher Ebene vorgenommen. Für den Titanic-Datensatz ist es nun möglich, für alle Personen im Testdatensatz vorherzusagen, ob und mit welcher Wahrscheinlichkeit sie das Unglück überlebt haben.
Und was ist mit Jack und Rose?
Die Daten werden als neue Testdaten behandelt und manuell als Data Frame abgespeichert. Anschließend wird das Modell mit der predict-Funktion auf die Daten angewendet.
Das Ergebnis ist eindeutig: Das Ende des Liebesdramas um Jack und Rose und die perfekte Dramaturgie sind der Beweis dafür, dass James Cameron nicht nur ein außergewöhnlicher Regisseur und Drehbuchautor ist, sondern auch über ein ausgeprägtes analytisches Verständnis verfügt.
Denn das Schicksal der beiden Hauptfiguren scheint vorbestimmt gewesen zu sein. Unser Modell prognostiziert, dass Jack zu 88,9% das Unglück nicht überleben wird, wohingegen Rose eine Überlebens-wahrscheinlichkeit von 96,5% hat.
Weitere Data-Mining-Analysen
Der Titanic-Datensatz bietet noch eine Menge an Analysepotential. Natürlich können weitere Modelle ausprobiert werden, um eine bessere Vorhersage zu erhalten. Außerdem wäre es möglich, Feature Engineering mit anzuwenden, denn zum Beispiel die Variable Name (die in der Analyse oben nicht miteinbezogen wurde) enthält eine Vielzahl von Informationen, die auch eine Rolle spielen könnten, wie etwa Titel. Zudem könnte man anhand der Kabinennummer eventuell Rückschlüsse auf die Position der Rettungsboote ziehen. Eine weitere Idee wäre sich zu überlegen, unter welchen Voraussetzungen Jack überlebt hätte. Vielleicht hätte ein Ticket für die 2. Klasse schon ausgereicht. Oder hätte er überlebt, wenn er 3 Jahre jünger gewesen wäre? Es verstecken sich noch eine Menge interessanter Informationen in diesem Datensatz.
Viel Spaß beim Entdecken!
Datenmanagement, Machine Learning und Visualisierungen: Mit den führenden eoda R-Trainings werden Sie zum Data-Science-Experten.