
Neues YUNA-Release
Agile Softwareentwicklung ist in aller Munde – auch wir haben uns dem agilen Manifest verschrieben.
Im engen Austausch mit unseren Kunden und durch die Erfahrungen, die wir in unseren Projekten sammeln, entwickeln wir YUNA in kurzen Sprints kontinuierlich weiter.

Neues YUNA-Release
Agile Softwareentwicklung ist in aller Munde – auch wir haben uns dem agilen Manifest verschrieben.
Im engen Austausch mit unseren Kunden und durch die Erfahrungen, die wir in unseren Projekten sammeln, entwickeln wir YUNA in kurzen Sprints kontinuierlich weiter. Ein schönes Zeichen, gerade auch in Zeiten von Corona, wenn das Team so gut zusammenspielt und es schafft die selbst gesetzte Roadmap zu verfolgen!
HINWEIS: Seit Anfang des Jahres sind wir in einen neuen Entwicklungsmodus gewechselt: Den Longterm-Sprint (LTS). Nach wie vor entwickeln wir agil in 4-wöchigen Sprints. Diese ordnen wir nun als „Zwischen-Sprints“ dem LTS unter. Daher kommt es zu einem größeren Versionssprung.
Sie möchten weiterhin informiert über den aktuellen Entwicklungsstand bleiben? Sprechen Sie uns an!
2.16
Mit der neuen Version 2.16 sind nicht nur funktionelle Neuerungen in YUNA implementiert worden. Um noch mehr Stabilität zu garantieren und die Entwicklungszeit unserer Sprints zu beschleunigen, haben wir uns entschlossen einen signifikanten Teil der Codebasis zu erneuern und uns von AngularJS zu lösen.
Design Aktualisierung
Die einzelnen Farben in einer Skala haben dank CSS-Variablen einen definierten Einsatzzweck, was das Anpassen der eingesetzten Themes noch einfacher macht.Durch diese Neuerung kann in YUNA fortan auch ein Dark-Mode verwendet werden, der optisch perfekt zum Light Mode passt und die gleichen Akzentfarben nutzt. Dabei sorgt das zugrundeliegende Farbschema dafür, dass eine optimale Lesbarkeit für beide Varianten gewährleistet werden kann. Jeder Nutzer kann selbst entscheiden, welches Design er nutzen möchte und dieses via eines dedizierten Schalters im Header wechseln.
Überarbeitete Ladeanzeige
User-Management
Aktuell arbeiten wir an einer Funktion, durch die alle User eine Profilseite erhalten, in der sie ihre persönlichen Daten selbst ändern können.
Als ersten Schritt in diese Richtung haben wir in 2.16 ein neues Admin-GUI implementiert, durch welches neue Nutzer angelegt werden können, die sich über Active Directories authetifizieren.
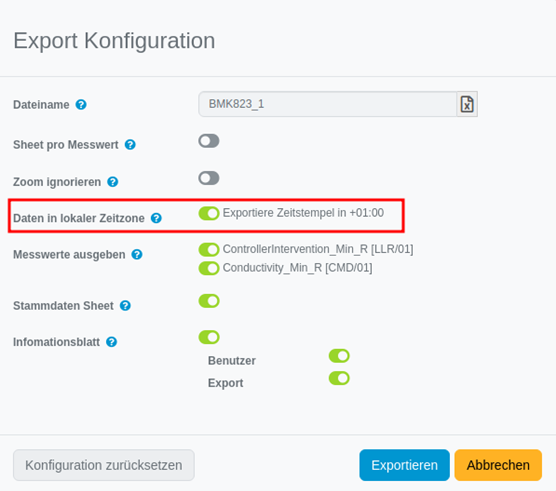
Konfigurierbare Zeitzonen im Export
Quality of Life Features
Im Zuge der neuen Version haben wir mehrere Features ergänzt, die den Nutzungskomfort erhöhen und Usern mehr Service bieten sollen:
- Jobmanager: Das Bestätigungsfeld enthält nun den Namen des abzubrechenden Jobs
- Die Sortierung in den Tabellen-Widgets erhält eine bessere alphanumerische Sortierung.
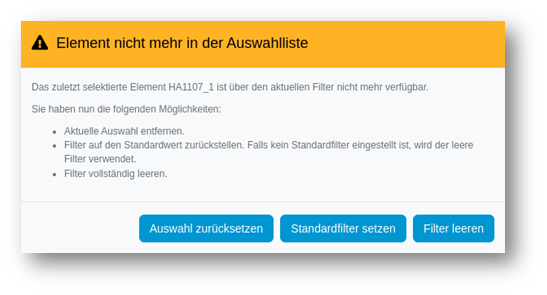
In textbaiserten Spalten wird der Wert „10“ nun nicht mehr nach den Werten „2“, „3“ etc. einsortiert, sondern wird als Zeichenkette in die entsprechende Position der „1er“ eingefügt. In einer Spalte vom Typ „Number“ werden Zahlen hingegen nach dem eigentlichen Wert sortiert, d.h. hier würde die „10“ nach Werten wie „2“ oder „3“ folgen. - Deeplinks und Filter: In YUNA lassen sich Dashboards bequem per Deeplink teilen. Dabei werden alle Einstellungen übernommen, inklusive ausgewählter Filter und der Auswahl in der Single Selection (bspw. um sich die Messkurve eines bestimmten Sensors anzeigen zu lassen). Ruft man nun jedoch einen etwas älteren Deeplink auf und ein in der Single Selection ausgewähltes Objekt ist mittlerweile nicht mehr Bestandteil des zuvor definierten Fitlersets, so war man bislang gezwungen die Auswahl in der Single Selection zurücksetzen. Die Folge war, dass man den Filter erst selbst ändern und das entsprechende Objekt erneut einstellen musste. Kommt es in der Version 2.16 jedoch zu diese Situation, so erhalten die User nun eine Benachrichtigung mit zusätzlichen Optionen (um das ausgewählte Objekt auf Wunsch zu erhalten): Das vollständige Zurücksetzen der eingestellten Filter, die Rückkehr zum Standardfilter oder – wie bisher – das Zurücksetzen der Singel Selection Auswahl.

- Eingabevalidierung: Im DataGrid Widget besteht nun die Möglichkeit von Usern eingegebene Werten (string, number, date und boolean) bereits unmittelbar bei der Eingabe in der Oberfläche gemäß zuvor definierter Kriterien zu prüfen. So kann bspw. gesichert werden, dass eingegebene Zahlenwerte einen gewünschten Zahlenbereich (z.B: max. 100%) nicht unter- bzw. überschreiten oder dass ein Enddatum zeitlich tatsächlich nach dem Startdatum terminiert ist.
Breaking Changes
- Im Rahmen der Eingabevalidierung werden neue Funktionen von VSCode genutzt, sodass für die Dashboard-Entwicklung nun mind. die Version 1.75.0 von VSCode (Januar 2023) benötigt wird.
- Im Zuge des Refactorings und der Abkehr von AngularJS wurde auch die Datums-Bibliothek ausgetauscht, die neue, standardisierte Datumsformate, sodass die bisher genutzten Datumsformate zeitnah aktualisiert werden müssen.
2.15
Fehlerminimierung & Sicherheit: Validierung von Eingaben
Mit der neuen Eingabevalidierung werden Werte bzw. Eingaben und Änderungen von Nutzerinnern und Nutzern nun vor der Weiterverarbeitung geprüft. So kann direkt verifiziert werden, ob eine Werteingabe der zuvor definierten Bedingungen entspricht, beispielsweise ob sich im DataGrid-Widget der Wert in einem Feld für Prozenteingaben zwischen 0 und 100% befindet.
Neuer DateService
Der DateService zur Nutzung von Datumsformaten, wurde überarbeitet, um auch in Zukunft noch verlässlicher zu funktionieren. Aufgrund dieser Umstrukturierung müssen bisherige Datumsformate ausgetauscht werden, insofern sie nicht bereits dem jetzt als Standard definierten Unicode Standard entsprechen.
Beispiele für neue Formate:
| Angabe | Format | Beispiel |
| short | yyyy-MM-dd | 2016-06-05 |
| long“ | yyyy-MM-dd HH:mm:ss.SSS | Englisch:2016-06-05 13:22:24.000
Deutsch:2016-06-05 13:22:24,000 |
| default) | yyyy-MM-dd HH:mm:ss | 2016-06-05 13:22:24 |
Standortabhängige Datumsformatierung
In der Formateinstellung „long“ wird abhängig von der Lokalisierung Ihres Browsers das entsprechend lokalisierte Format angewandt. Im Falle einer deutschen Lokalisierung wird eine deutsche Formatierung gewählt. In allen anderen Fällen, die englische. Weitere Informationen sind der in YUNA aufrufbaren Dokumentation zu entnehmen.
Anwenderfreundlichere Einzelselektion (SingleChoicedirective)
In YUNA lassen sich durch die intelligenten Filter zu einer ausgewählten Einheit (z.B. ein Gerät) anzeigen, die zuvor aus einer Liste ausgewählt wurden.
Durch die Auswahl bestimmter Filter, war es bisher möglich, dass ausgewählte Element in der Einzelauswahl nicht verfügbar waren. Dies war bspw. der Fall, wenn ein Filter über zuvor gespeicherten DeepLink aufgerufen wurde und zum Zeitpunkt der DeepLink-Erstellung in diesem Filter ein Element hinterlegt war, welches nun nicht mehr Bestandteil des aktuellen Filtersets ist. In 2.15 wurde nun die Möglichkeit geschaffen, die Auswahl in der Einzelselektion beizubehalten: Dabei wird die Filterauswahl auf den Standardfilter oder den leeren Filter gesetzt. Die Option, die Einzelselektion zurückzusetzen und den geladenen Filter anzuwenden bleibt jedoch erhalten.
Zusätzliche Abfrage Job-Übersicht
In YUNA liefert mithilfe von Skripten Antworten auf verschiedenste Fragestellungen, die die NutzerInnen und Nutzer stellen oder ermöglicht mit diesen Skripte umfassende Automatisierungen von Prozessschritten. Der Zusammenschluss aus Fragestellung und Skript, bzw. das beabsichtigte Ziel wird im YUNA-Kontext „Sachverhalt“ genannt. Die Ausführung dieser Skripte kann in YUNA manuell oder zyklisch gesteuert werden. Diese Steuerung wird im YUNA-Kontext „Job“ genannnt. In 2.15 wird beim Abbrechen eines Jobs, eine zusätzliche Abfrage zur Gegenprüfung inklusive Auflistung der betroffenen Job-Namen angezeigt.
Kleinere Bugfixes
Es wurden mehrere Fehler bei den Filtern und in der Job-Übersicht behoben. In der Filterverwaltung werden in den Metadaten wieder alle Besitzerinnen und Besitzer angezeigt Es wurde ein Bug behoben, durch den Benachrichtigungen z.T. nicht angezeigt wurden, wenn ihr Timestamp identisch zu denen anderer Benachrichtigungen waren.
2.14
Design System
Zum Ausbau und Überarbeitung der Benutzeroberfläche wird die Komponenten-Bibliothek, aus denen sich die Dashboards entwickeln lassen, stetig erweitert. Es wurde die Basis für weitere Komponenten geschaffen.
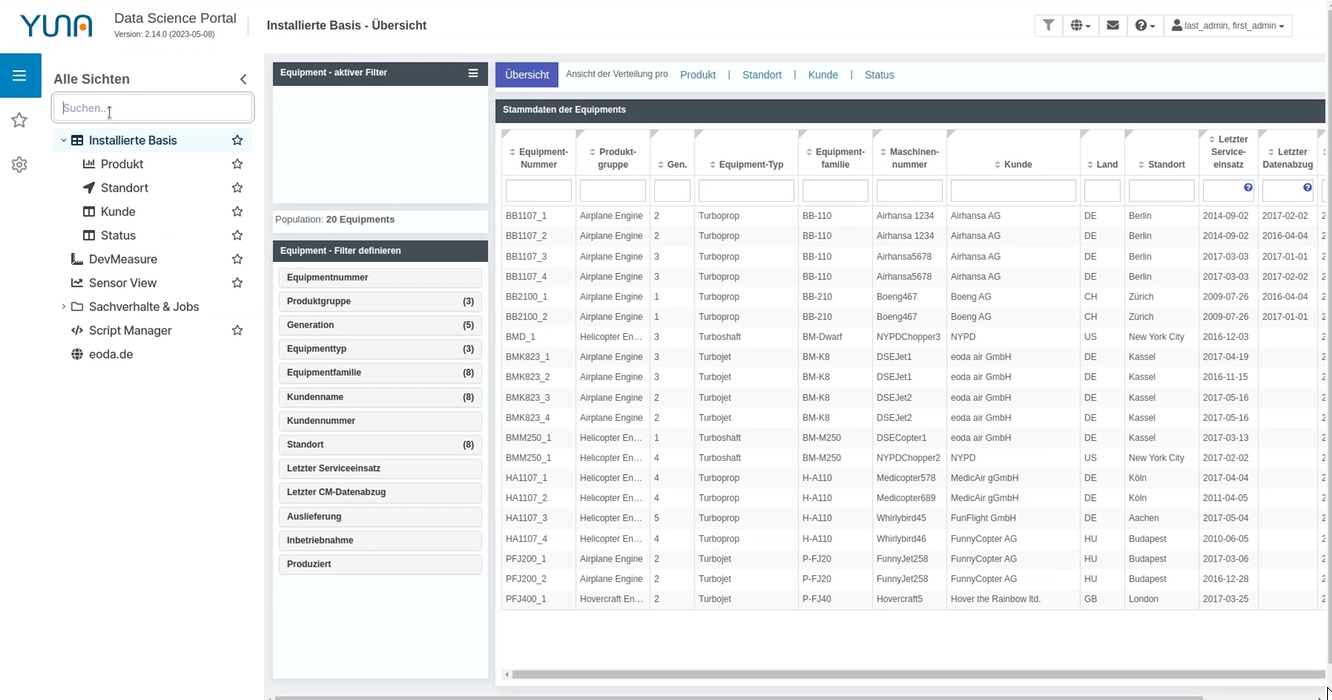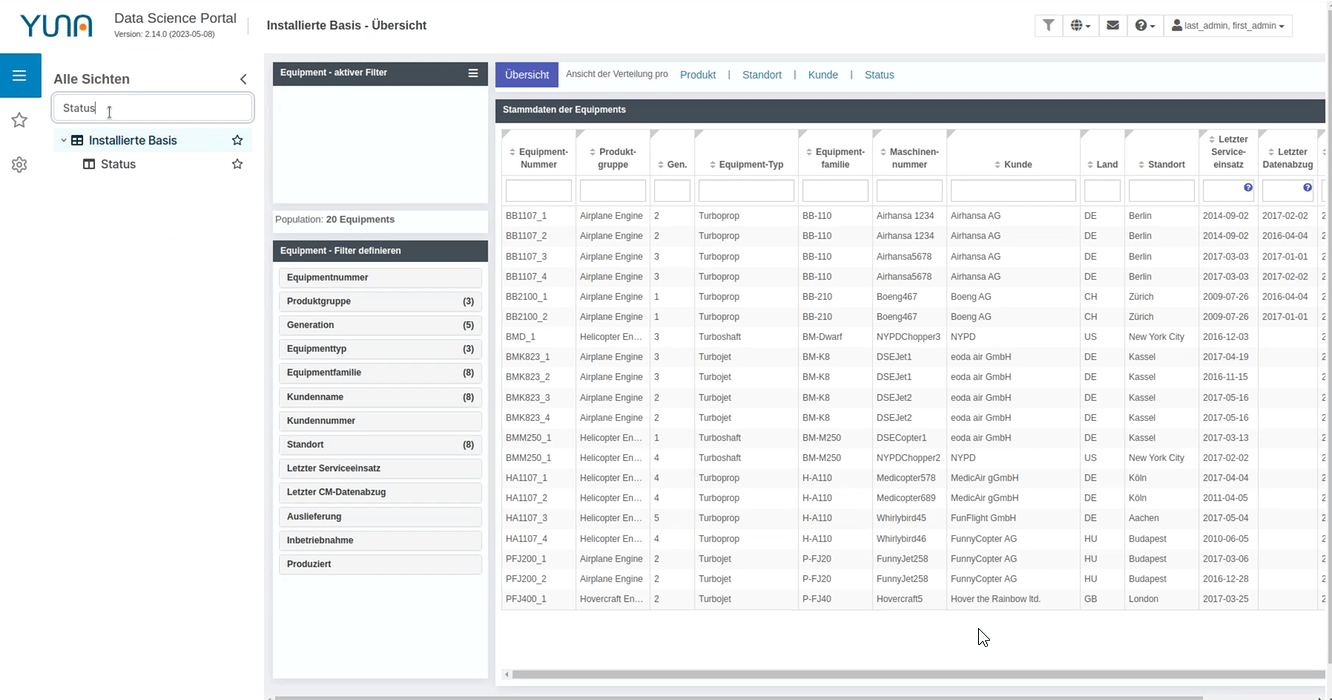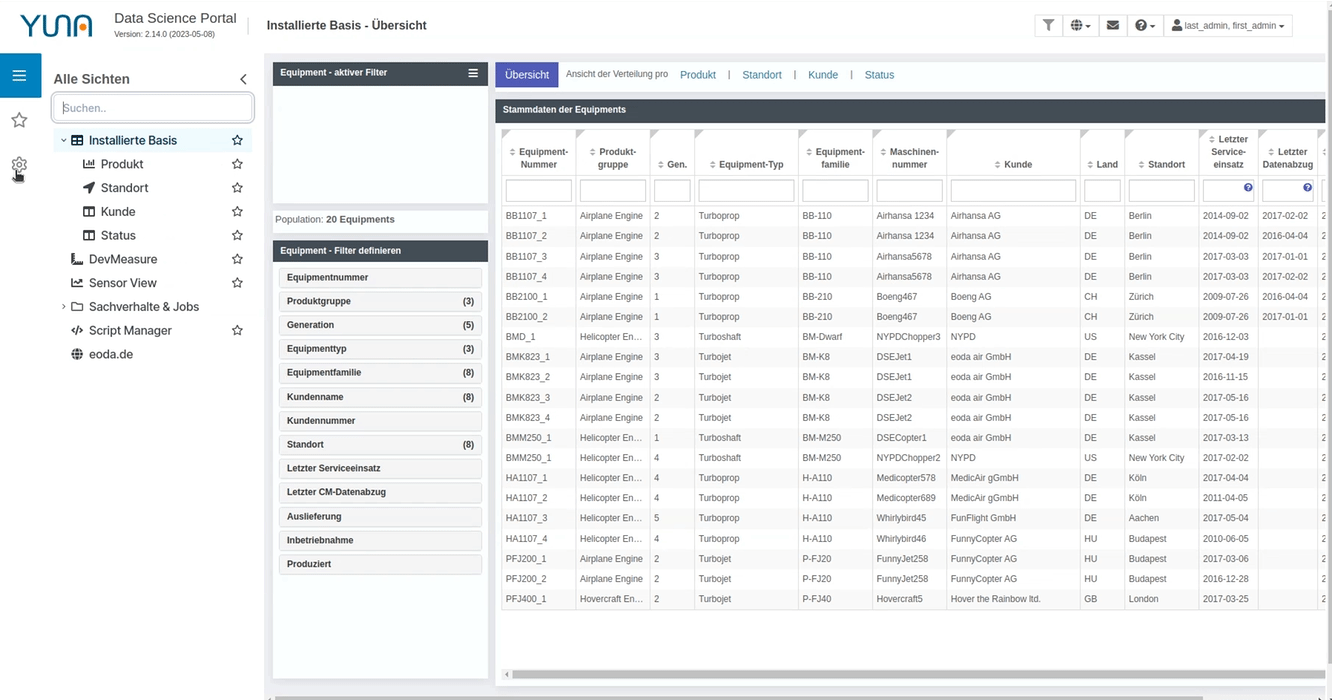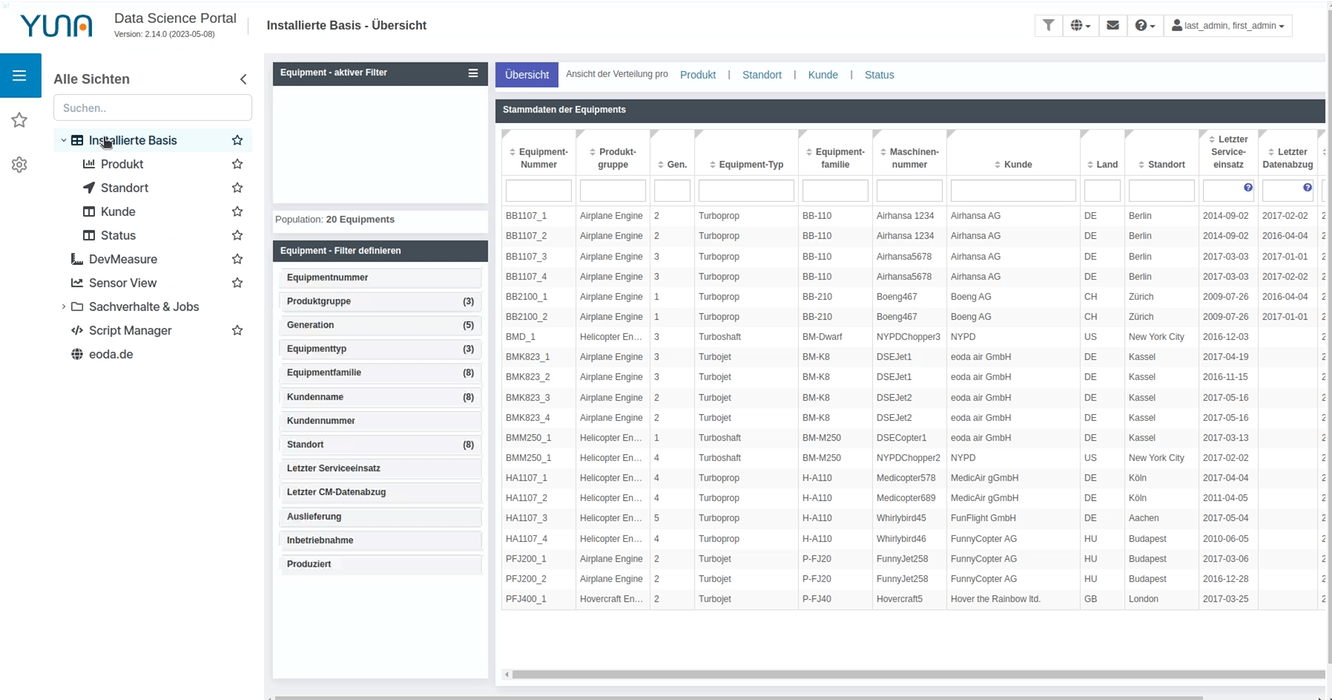
Update der Navigationsleiste
Unter anderem wurde die Navigationsleiste bzw. die Seitenleiste aktualisiert. Sie lässt sich nun genauer und intuitiver definieren und erleichtert so die Navigation durch verschiedene Dashboards. Zudem lassen sich Dashboards bzw. Ansichten als Favoriten festlegen und es eine Suchfunktion wurde zugefügt.
2.13
Stabilitätsverbesserung bzw. Systemhärtung
Im unternehmensweiten Einsatz als zentrale Plattform für Datenzugriff, -visualisierung und Ausführen von Analysen kann es in speziellen Ausnahmefällen vorkommen, dass von verschiedenen NutzerInnen zu viele parallele Anfragen an die Datenbank mit hohen Datenmengen gestartet wurde. Dies konnte zu einer Verlangsamung des Systems führen. Ab sofort lassen sich verschiedene Werte limitieren:
- Maximale Anzahl der Queries
- Globales Zeitlimit
- Größe der Query-Warteschlange
Zudem wurden die Metriken im Prometheus-Monitoring entsprechend angepasst:
- Anzahl wartender, sich in Ausführung befindlicher und blockierender Queries
- Aktuelle Wartezeit
- Durchschnittswerte der letzten 10/100/1000 Queries
- Lifetime-Statistiken
2.12
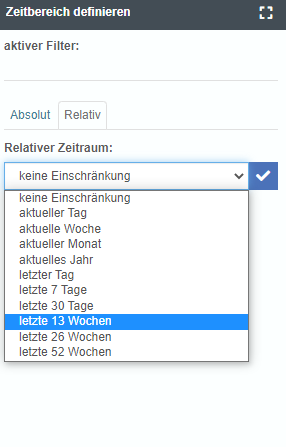
Komplette Überarbeitung des Datumsfilter
Stetige Verbesserung an allen Funktionen – wir haben den Datumsfilter zurück aufs Zeichenbrett gelegt und neu aufgezogen. Dadurch hat sich die Bedienbarkeit deutlich verbessert. Auch wurde mit dem Datumsfilter eine Komponente des neue Design-Systems von YUNA implementiert.
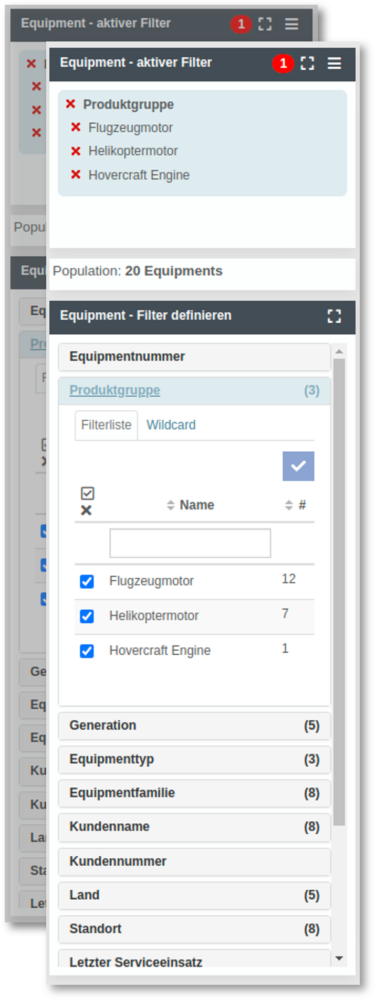
Auswirkungen von Filterdefinitionsänderungen
In YUNA lassen sich individuelle smarte Filter-Sets zusammenstellen, ändern, teilen und weiterverwenden. Wenn sich die grundlegenden Definitionen der Filter ändern, kann dies unterschiedliche Auswirkungen haben. Mit Version 2.12 haben wir verschiedene Aktionen implementiert:
- Fehlerhafte Filterkategorien werden vor der Anwendung entfernt. Kategorien sind fehlerhaft, wenn die Kategorie aus der Definition entfernt wurde oder der Filter-Typ geändert wurde.
- Verknüpfte Jobs (Ausführungen von Skripten) werden abgebrochen, sofern fehlerhafte Filter genutzt werden.
- Kennzeichnung entsprechender Filter.
- NutzerInnen erhalten eine Kurzbenachrichtigung.
2.11
Update von YUNA Lang
YUNA Lang ist eine XML-orientierte Syntax, mit der sich Dashboards in YUNA konfigurieren, ändern und erstellen lassen. Die Möglichkeiten der individuellen Anpassungen wurden weiter ausgebaut. Unter anderem können Label-Typen definiert werden, Timestamps formatiert oder Parameter im HTML-Widget direkt im Template verwendet werden.
2.10
Verbesserung des YUNA-Monitorings
Um den System-Zustand der YUNA-Instanzen wird das externe Tool „Prometheus“ genutzt. In Version 2.10 wurden der Endpunkt, mit dem Prometheus und YUNA interagieren so umgestellt, dass nun jmx, statt wie zuvor jvm Metriken bereitstellt.
Diese unterscheiden sich teilweise inhaltlich und durch ihre Benennung, liefern dennoch detaillierte Informationen über das System. Zudem werden YUNA spezifische Metriken, wie die Anzahl der verbundenen Agenten, ebenfalls über den Endpunkt exportiert. Ein Endpunkt wurde in diesem Zuge entfernt.
2022
Mehr erfahren
2.9
Test IDs für Automatisierte Oberflächentests
Die automatisierten End-to-End-Tests von Dashboards, beispielsweisen durch Selenium oder Playwright, wurden weiter optimiert. Durch die Einführung fester IDs in verschiedenen Komponenten lassen sich diese nun einfacher innerhalb der HTML-Struktur identifizieren. Die ID-Vergabe der Widgets lässt sich nun ebenfalls mit festen Werten überschreiben.
2.8
Ob im Condition Monitoring & Predictive Maintenance, bei Lastprognosen im Energienetz oder im Sales Forecast – mit schnell begreifbarer Visualisierung lassen sich aus Daten schneller Erkenntnisse gewinnen sowie Entscheidungen und Handlungen ableiten.
Mit der neuen Version haben wir die Visualisierungsmöglichkeiten von YUNA erweitert. In verschiedene Diagramm-Optionen, jeweils mit unterschiedlichen Varianten, vereinfacht YUNA die explorative Datenanalyse in einem breiten Spektrum.
Unterstütze Diagramm-Arten:
- Linien
- Balken
- Kreis
- Scatter
- Boxplot
- Candelstick
- Heatmaps
- Graphen
- Tree(map)
- Sunburst
- Sankey
- Funnel
- Gauge
- Uvm.
Ready-set-go – Nun noch schneller mit YUNA starten!
Mit den Erfahrungen beim Aufsetzen von YUNA bei unseren Kunden, haben wir die Installation/das Deployment von YUNA stark vereinfacht. Schon vorher ließ sich YUNA per Docker-Container in nahezu jeder Infrastruktur einsetzen – hier haben wir nochmal an verschiedenen Stellschrauben gedreht und die Zeit, vom initialen Deployment bis zum User-Login drastisch gesenkt. Gleichzeitig bewirkt die Änderungen, dass YUNA-Instanzen und Backups sich, z.B. in Cloud-Strukturen, auf Knopfdruck noch schneller hochfahren bzw. einspielen lassen. Dadurch sinkt die Downtime im produktiven Einsatz für Automatisierungs und Analytik-Projekte – und erlaubt nun den noch komfortableren Einsatz von Testsystemen.
Out-of-the-box vs Anpassung? Das Systempanel
Mit YUNA ermöglichen wir es unseren Kunden eine Plattform einzusetzen, die sie auf ihre Bedürfnisse bei der Umsetzung datengestützter Use Cases bzw. der Automatisierung von Geschäftsprozessen anpassen können.
Das Systempanel vereint verschiedenste Optionen, Einstellungen, die Möglichkeit Berechtigungen zu ändern und den Systemzustand zu beobachten.
2.7
Verbesserung der Systemperformance
Mit YUNA geben wir Usern die Möglichkeit umfassende Daten schnell und direkt zu analysieren und auch zur Prozessautomatisierung zu nutzen.
Um die Systemperformance zu verbessern, haben wir die Möglichkeiten geschaffen, sowohl ein globales (also systemweites) als auch ein use-case-abhängiges Maximum für Datenabfragen zu definieren. Diese Beschränkungen lassen sich durch die AdministratorInnen konfigurieren. Im Sinne der Transparenz für den User, dass der Ergbnisbereich eingegrenzt wurde, wird diese Obergrenze auch im Table und DataGrid Widget angezeigt. Darüber hinaus zahlt das Update als Vorbereitung auf die anstehende Umsetzung einer Lazy Loading Funktionalität im DataGrid Widget ein.
Typisierung von IO-Channels
Durch die IO-Channels kommunizieren die einzelnen Widgets miteinander, tauschen also Informationen aus und reagieren aufeinander. Durch das Einführen des globalen und benutzerdefinierten Maximums wurden auch einige Änderungen am IO-Provider vorgenommen:
DataID-Provider
In YUNA werden Daten aus Datenbanken und Skripte einer eindeutigen ID zugewiesen. Sie ist das Bindeglied zwischen den Widgets – Komplexe Prozesse lassen sich so einfacher darstellen und umsetzen. In diesem Zuge gibt es einige Breaking Changes:
- Output-Objekt Eigenschaften „rows“ und „columns“ wurden entfernt
- Die Daten des Output-Objekts finden sich nun immer an der Eigenschaft „data“
- Werden in nutzerdefinierte Templates (z.B. im DataGrid- oder Form-Widget) die Eigenschaften „rows“ oder „columns“ genutzt, müssen diese durch „data“ ersetzt werden
DataGrid-Widget und HTTP-Provider
Mit dem DataGrid-Widgt werden in YUNA Tabellen dargestellt. Es ermöglich verschiedene Funktionen wie z.B. Export und direkte Visualisierung in Form von unterschiedenen Diagrammen.
Änderungen:
- Um Daten vom HTTP-Provider an den DataGridWidget InputChannel „data“ zu übergeben, muss der neue OutputChannel „responseBody“ verwendet werden
Formular-Widget
Das Form-Widget dient zur Darstellung von Formularen, bzw. Eingabefeldern.
Änderungen:
- Der Output Channel gibt die eingegeben Daten nun direkt als Objekt zurück
- nutzerdefinierte Templates, welche den Form-Widget Output benutzen, müssen nun direkt auf die Eigenschaften des Objects zugreifen
- Bis V2.6: <ChannelName>[0].<Eigenschaft>
Ab V2.7: <ChannelName>.<Eigenschaft>
2.6
Noch sicherer: Verschlüsselung von Zugangsdaten, die in Skripten genutzt werden
Zur Anbindung von Drittsystem wie bspw. Jira, Microsoft Dynamics etc., ist es oft notwendig, Zugangsdaten in Skripten zu hinterlegen. Um diese vor der Einsicht durch Dritte zu schützen, werden die entsprechenden Zugangsdaten fortan verschlüsselt in der Datenbank abgespeichert. Die Entschlüsselung, die nur innerhalb von Skripten möglich und YUNA so zu keinem Zeitpunkt verlässt, erfolgt mittels des individuellen Schlüssels des jeweiligen YUNA-Servers.
Optimierung der Nachverfolgung fehlerhafter und abgebrochener Analysen
Kommt es in YUNA zum Abbruch von Analyseausführungen, z.B. wegen technischer Probleme oder wegen falsch gewählter Parameter, so werden stets temporäre Daten zur späteren Nachverfolgung abgelegt, um potenzielle Fehler besser analysieren zu können. Mit der Zeit können diese Daten jedoch zu einem größeren Speicherverbrauch auf dem ausführenden System führen.
Um das System dauerhaft sauber zu halten, werden diese Daten mit der neuen Version im temporären Verzeichnis des Betriebssystems abgelegt, sodass die umfassenden Speicherverwaltungsmechanismen des Betriebssystems dazu genutzt werden können, die temporären Dateien zu bereinigen.
Ständige Verbesserung: Smartes Logging
Systemlogs sind oft unübersichtliche, lange Textdateien. Grundsätzlich gibt es bei Log-Dateien immer den Konflikt zwischen Vollständigkeit und Übersichtlichkeit. Gab es in YUNA bislang zahlreiche Fehler, die unabhängig von der Kritikalität meist als ERROR klassifiziert wurden, so haben wir den Usern nun die Möglichkeit gegeben verschiedene Log-Level zu wählen:
- ERROR: Alle Fehler, die denn Betrieb von YUNA beeinträchtigen können
- WARN: Sonstige Fehler, z.B. durch die Bedienung
- INFO: Sonstige Ausgaben
- DEBUG: Testausgaben
Auf diese Weise können User direkt erkennen, ob eine gemeldete Unstimmigkeit eine administrative Handlung erfordert oder lediglich ein Hinweis auf etwas gegeben werden sollte. Darüber hinaus lassen sich verschiedene Log-Dateien für verschiedene Nutzer-Gruppen anlegen, was zu einer schnelleren Fehler-Identifikation führt.
Optimierung des Zeitfilters
Um schnell zum Ziel zu kommen und die gesuchte Information zu finden, haben wir den Zeitfilter angepasst. In der neuen Version lässt sich in YUNA nicht nur das Zeitformat als solches anpassen, in YUNA selbst können die Daten nun noch einfacher bis hin zur Millisekunde gefiltert werden. Zur einfacheren Nutzung haben User die Wahl, die gewünschten Zeiten entweder als Text- oder Nummernfeld einzugeben.
2.5
Noch sichereres Deployment von Dashboards
Mit YUNA Lang als Markup-Sprache ist es möglich eigene Dashboards in YUNA zu entwickeln bzw. bestehende anzupassen. Mit der neuen Version haben wir die VSCode Erweiterung weiter verbessert, sodass YUNA Lang nun offiziell den Status „Ready for Production“ hat. Zu den Neuerungen zählen u.a. folgende:
- Passwörter, die für das Deployment benötigt werden, können nun je Projekt in einem Passwort-Speicher hinterlegt werden. So müssen diese nicht mehr bei jedem Deploymentvorgang neu eingegeben werden
- Über eine separate Projektdatei wird zusätzlich die Projektstruktur, beim Ändern / Erstellen der Dashboards sichergestellt. So kann z.B. gewährleistet werden, dass beim Öffnen eines Projekts der richtige Ordner gewählt wurde
- Neu ist außerdem der automatische Versionsabgleich zwischen der YUNA Lang Erweiterung für VSCode und der YUNA-Instanz. Auf diese Weise wird die Kompatibilität von Dashboards über verschiedene Instanzen hinweg sichergestellt
- Zudem können nun innerhalb der Dashboard-Projekte Standards für die Deployment-Profile und RefTags definieren, wodurch der Deploymentvorgang noch einmal einfacher ist und schneller ablaufen kann. RefTags dienen dazu, zwischen verschiedene Dashboards und Dashboard-Ketten (also zusammenhängende individuelle Dashboards) zu springen, was insbesondere beim Testen neu erstellter Dashboard-Ansichten enorm praktisch sein kann, wenn diese erst einzelnen Nutzern zugänglich gemacht werden sollen.
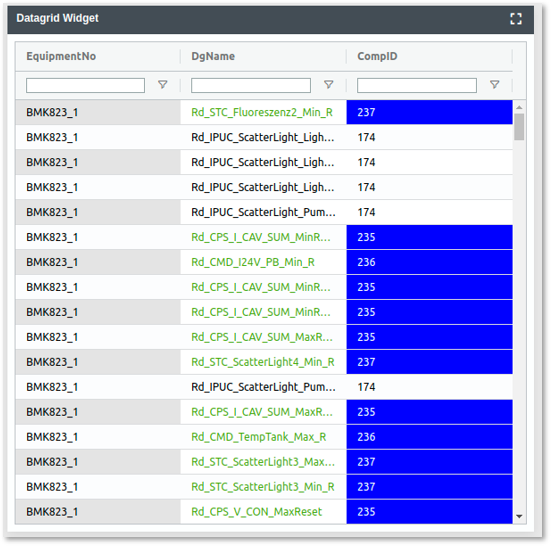
Gruppieren von Tabellspalten im DataGrid Widget
Bei großen Tabellen kann die Übersicht schnell leiden. Ein besonderer Fokus von YUNA liegt aber genau darin, die Übersicht beim Arbeiten mit vielen Informationen und Daten für User so einfach wie möglich zu gestalten.
In Version 2.5 erhält das DataGrid Widget, welches zur Darstellung von Tabellen genutzt wird, die Möglichkeit Spalten, die z.B. thematisch zusammen gehörenzusammengehören, zu gruppieren. Zusätzlich lassen sich diese gruppierten Spalten ein- bzw. ausklappen, sodass man stets so viele Informationen im Blick hat, wie man gerade benötigt.
2.4
Bestehende Datensätze einfach erweitern
Importierte Datensätze zur weiteren Verarbeitung haben in gängigen BI- und Analysetools oft einen Nachteil : Sie sind starr und nahezu unveränderlich. Aktualisierungen oder neue Informationen lassen sich oft nur schwer zufügen. Und wenn doch, dann werden die aktualisierten Datensätze als separate Kopie abgelegt , den es mit dem ursprünglichen Datensatz zu verbinden gilt. In YUNA werden Datensätze virtuell gespiegelt und lassen sich ähnlich einer Versionierung, um manuelle Eingaben erweitern:
- Möglichkeit A: Inhalte bestehender Zeller sind änderbar. Die Änderungen werden im entsprechenden Datensatz aktualisiert.
- Möglichkeit B: Eingabe neuer Informationen durch Zufügen zusätzlicher Spalten.
Die neue Funktion eröffnet neben der eigentlichen Eingabe neuer Werte weitere Möglichkeiten: So lassen sich die Daten in den Tabellen beispielsweise durch eine zusätzliche Spalte labeln bzw. annotieren.
Durch die interne Filter-Logik in YUNA können diese Datensätze im Workflow-Manager dann direkt für neue Analysemodelle genutzt werden oder werden bei bestehenden Modellen genutzt.
Übersichtliche Tabellen
In YUNA können verschiedene Standorte / Teams aber auch einzelne Menschen auf derselben Datenbasis zusammenarbeiten. Dazu bietet YUNA verschiedene Sprachvarianten an. In der neuen Version haben wir die internen Übersetzungslogiken erweitert.
So lassen sich jetzt auch Filter-Sets [LINK], die von den Usern selbst erstellt werden, mit entsprechenden Übersetzungen versehen. Auf diese Weise können nicht nur neu-erstellte, sondern auch bestehende Filter für andere Sprachen sinnvoll angezeigt werden.
Automatisierte Deployment & Auslieferung von YUNA Lang
Mit YUNA Lang, lassen sich Dashboards in YUNA nicht nur erstellen, sondern auch bereits existierende Dashboards anpassen. Dabei lassen sich zwei Wege unterscheiden:
- User mit entsprechenden Rechten/Rollen erstellen eigene Dashboards. Und können sie entsprechend ausrollen.
- Dashboards werden durch Admins unternehmensweit oder für bestimmte Gruppen erstellt/geändert.
Für ersteren Fall wurde eine VS-Code Erweiterung zur Verfügung gestellt. Mit diesem Tool werden ebenfalls alle weiteren vorhandenen VSCode-Erweiterungen beim Deployment ebenfalls übernommen.
Für den zweiten Weg ist ein entsprechendes CLI-Tool erstellt worden, mit denen das automatisierte Ausrollen von Dashboards vereinfacht wird.
2.3
Es wurden verschiedene kleinere Bugs gefixt und an die Perfomance optimiert
2.2
Funktionsupdate des Imageviewers
Mit dem Imageviewer lassen sich in YUNA Bilder aus der Datenbank anzeigen. Neu hinzugekommen ist die Möglichkeit eine direkte Assoziation der Bilder mit den Informationen aus den Tabellen herzustellen.
Update zum Vollbildmodus
Der Vollbildmodus ist nun für alle Widgets in YUNA verfügbar.
2.1
Mehr Informationen über YUNA-Filter einsehbar
| Das Filter-System ist elementarer Bestandteil von YUNA und geht weit über das gängige Verständnis von sortieren/ausblenden von Informationen hinaus, wie man es von Excel oder in Online-Shops kennt. Die Filter in YUNA „kommunizieren“ mit den Dashboards, sie behalten ihre Einstellung auch beim Wechsel in andere Sichten/Dashboards bei – man muss also nicht jedes Mal dieselben Kategorien auswählen, wenn man eine andere Perspektive wünscht. Auch lassen sich die Filter verknüpfen, ändern und speichern sowie per „Wildcards“ also Platzhaltern weiter individualisieren. |
Zusätzlich lassen sich diese gespeicherte „Filter-Sets“ ganz einfach mit anderen teilen oder direkt bei der Erstellung neuer Dashboards oder sogar der Entwicklung ganz neuer Dienste nutzen. So kann aus einer klassischen BI-Sicht, der Filter genutzt werden, um einen neuen Anwendungsfall zu konzipieren, wenn z.B. eine anderes Analysemodell genutzt werden soll – das verkürzt die Entwicklungszeit einzelner Use Cases.
Wir haben für die Übersichtlichkeit die API, welche die YUNA-Filter verwaltet geöffnet. Alle Informationen, die im jeweiligen Filter genutzt werden, lassen sich nun direkt einsehen.
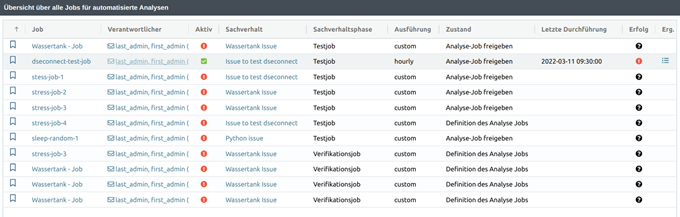
Duplizieren von Jobs
YUNA ermöglicht es Usern nicht nur Informationen schnell durch Visualisierungen zu begreifen, sondern auch die zugrunde liegenden Modelle auszuführen und zu verwalten, ohne dabei auf einen Data-Science-Hintergrund zurückzugreifen. Dieses Ausführen (zyklisch oder manuell) wird über Jobs gesteuert. Entlang des Workflows enthalten Jobs Informationen wie bestimmte Parameter, Ausführungszeiten, Verantwortlichkeiten und Filter.

Mit Version 2.1 ist es nun möglich Jobs ganz einfach zu duplizieren. Dadurch lassen sich neue Jobs schnell anlegen oder aber auch schnell für neue/unterschiedliche Use Cases anpassen. Gleichzeitig haben wir die Job-Übersicht erweitert, so dass dort die entsprechende Phase des Workflows, in der sich die einzelnen Jobs befinden, standardmäßig angezeigt werden.
Major Update – 2.0
Mit der neuen Version basieren nun alle internen wie externe Strukturen auf Java 11. Im Zuge dieses großen Updates haben sich „unter der Haube“ viele Änderungen ergeben.
Im Zuge des Updates von Java 8 auf Java 11 haben auch verschiedene Pakete im Backend wie das Java-Framework OSGI, der Webserver jetty und der REST-Framework JAX-RS Upgrades erhalten, während Abhängigkeiten zum bis dahin noch parallel genutzten Spring-Framework entfernt wurden.
Zudem wurden die Umbauarbeiten genutzt die Strukturierung nach Backend und Frontend zu überarbeiten.
Im Zuge dieser Neustrukturierung haben wir auch gleich den Weg für weitere umfassende Änderungen geebnet – wodurch wir unsere Vision von YUNA noch schneller umsetzen können.
Aktuell arbeiten wir u.a. an…
- einem kompletten Redesign der Benutzeroberfläche,
- neuen Komfortfunktionen für die End User,
- Umfassenden, automatisierte Visualisierungsmöglichkeiten,
- noch mehr Möglichkeiten YUNA mit verschiedensten Anwendungen agieren zu lassen.
- der Anbindung und Integration externer Anwendung.
Wir freuen uns auf die Zukunft und die neuen Möglichkeiten, mit denen wir datengestützte Intelligenz, Kompetenz und Entscheidungen noch besser in spürbare Mehrwerte transformieren werden!
1.35
DataGrid – die bessere Tabelle
In der neuen Version haben wir mit dem DataGrid Widget den Nachfolger des Table Widget eingeführt. Neben deutlichen Performance-Verbesserungen bei der dynamischen Darstellung großer Datensätze bringt das DataGrid Widget die Grundlage für eine Vielzahl neuer, spannender Features für die Anwendung mit:
- Interaktion
Integrierte Volltext-Suche in den jeweiligen Spalten
Verbessertes Zusammenspiel mit anderen Widgets, so lassen sich z.B. verschiedene Formatierungen und Funktionen z.B. durch Filter-Widgets ändern - Erweiterte Filter
Die abgebildeten Daten können nun auch mittels Vergleichsoperatoren (equals, lower than, higher than, in range etc.) gefiltert und eingegrenzt werden. - Übersichtlicher
Kombination verschiedener Stammdaten z.B. aus verschiedenen Datenbank-Spalten in einer einzigen Spalte
Spalten lasen sich beliebig in ihrer Breite verändern
Schneller Zusammenhänge erkennen – Integrated Charts
Das neue DataGrid bietet außerdem die Möglichkeit, Daten aus der Tabelle heraus direkt zu visualisieren! Dazu können die gewünschten Zellen einfach markiert werden, dann kann per Rechtsklick ein geeigneter Diagrammtyp gewählt werden, der sich auch im Nachhinein noch modifizieren lässt. Entsprechend lassen sich Verläufe aber auch Zusammenhänge noch schneller erkennen – natürlich lassen sich diese Diagramme dann wieder mit anderen YUNA-Usern teilen oder exportieren.
Weiteres:
- Spalten frei definierbar (Verschieben, Ändern der Spaltenbreite, Ausblenden, Anpinnen, Auto-Sizing)
- Infinite Scrolling statt Pagination
- Simple Umrechnung wie bspw. Wechselkurse direkt in der Tabelle statt über StoredProcedures
- Zellenselektion (Single & Multi)
- Export selektierter Zellen (CSV, Excel etc.)
- Aggregation ausgewählter Zellen (Summe, Durchschnitt etc.)
Ein einfaches Beispiel:
Zur Anzeige des weltweiten Maschinenstatus jeder Maschine mit zugehörigen Gesamtkosten in einem Condition Monitoring Portal, lassen sich in der Tabelle alle relevanten Funktionen, wie Standort (per GPS-Koordinaten und Kontaktadressen) und Maschinengeneration anzeigen. Über YUNA lassen sich nun per Filterwidget direkt in der Tabelle zusätzliche Informationen, wie Maschinenkonfiguration in einer neuen Spalte anzeigen lassen. Die Gesamtkosten, können dann sogar in verschiedenen Währungen tagesaktuell gewechselt werden (die Berechnung wird automatisch in der Tabelle durchgeführt), was die internationale Kommunikation vereinfacht.
Automatische Zuweisung von Vorfiltern
Vorfilter sind Sammlungen bestimmter Filter, die z.B. Datenbasis, auf die für die entsprechenden Gruppen relevanten Daten, eingrenzt – ohne getrennte Datentöpfe einzurichten.
Ab jetzt werden die verschiedenen einzelnen Vorfiltern den entsprechenden Usern automatisch zugewiesen
2021
Mehr erfahren
1.34
Kleinere Bugfixes und Performance-Verbesserungen
1.33
Vereinfachte Installation – YUNA jetzt als Container-Images verfügbar
Die Implementierung einer unternehmensweiten Data-Science-Plattform kann ein aufwändiger Prozess sein – zumindest war dies in der Vergangenheit so.
Damit YUNA jetzt noch schneller zum Einsatz kommen kann, stellen wir YUNA nun erstmalig als Container-Images zur Verfügung, welche Frontend-Server-Container, Backend-Container, Agenten sowie Liquibase umfassen und inklusive nginx in einem Docker-Compose-File bereitgestellt werden können. Damit ist der erste Schritt getan, um den Einrichtungsprozess der gesamten Plattform in Zukunft deutlich zu beschleunigen und noch komfortabler zu gestalten, damit sich YUNA bald noch einfacher in bestehende Strukturen integrieren lässt.
Favoritenmodus – schneller zum Ziel
Unterschiedliche Use Cases, verschiedene Skripte und eine Vielzahl unterschiedliche Analysejobs – da kann die Übersicht schon mal verloren gehen.
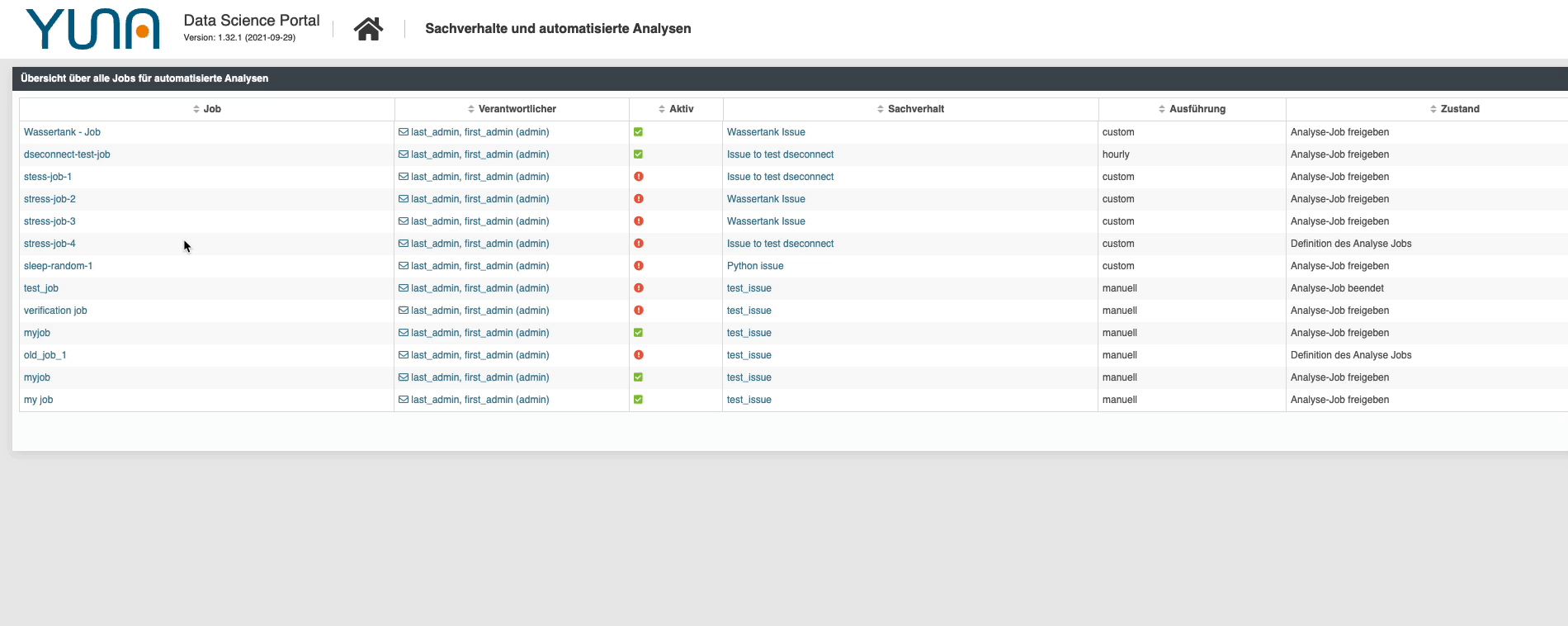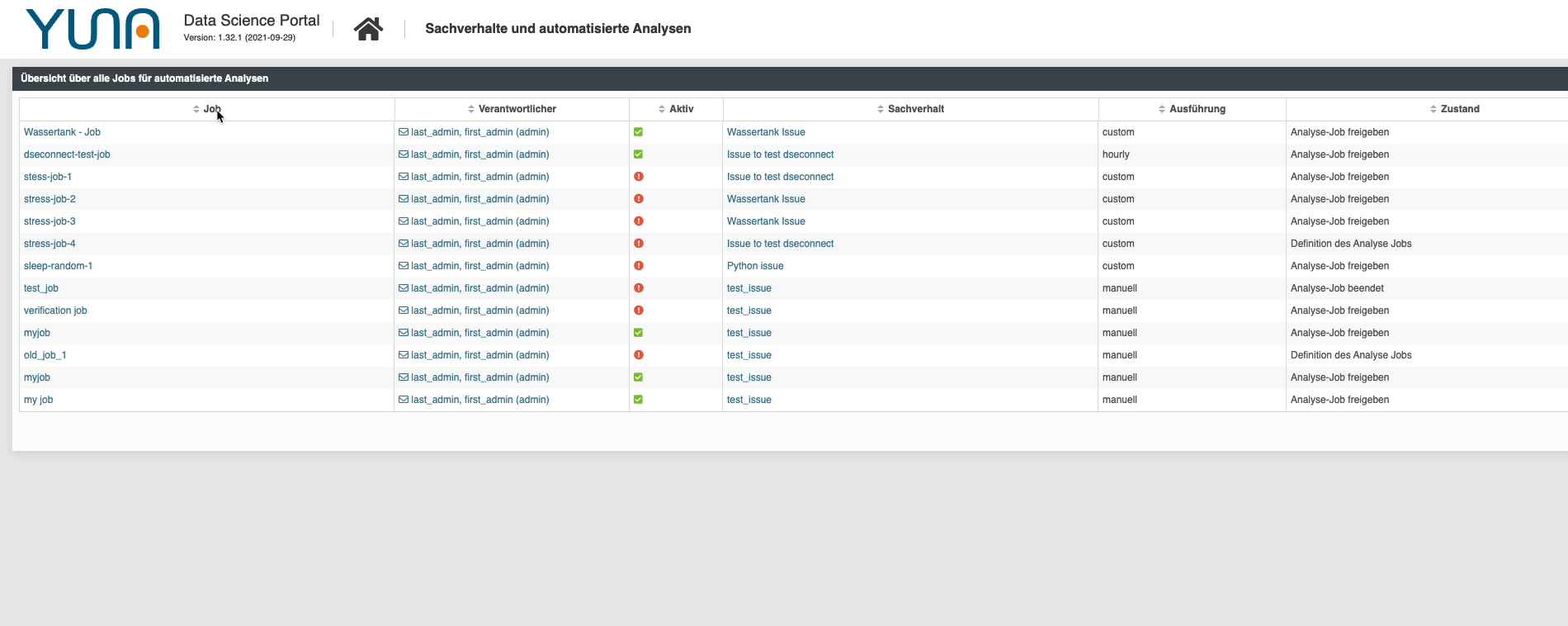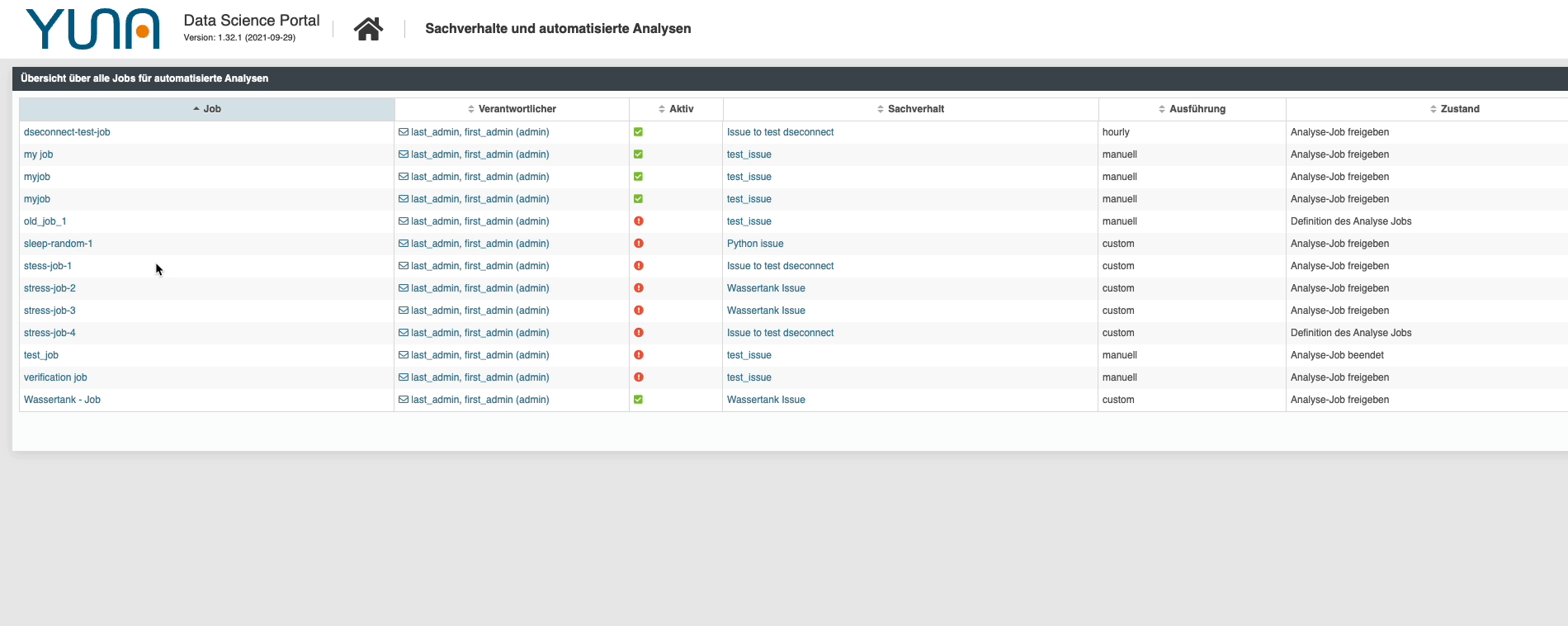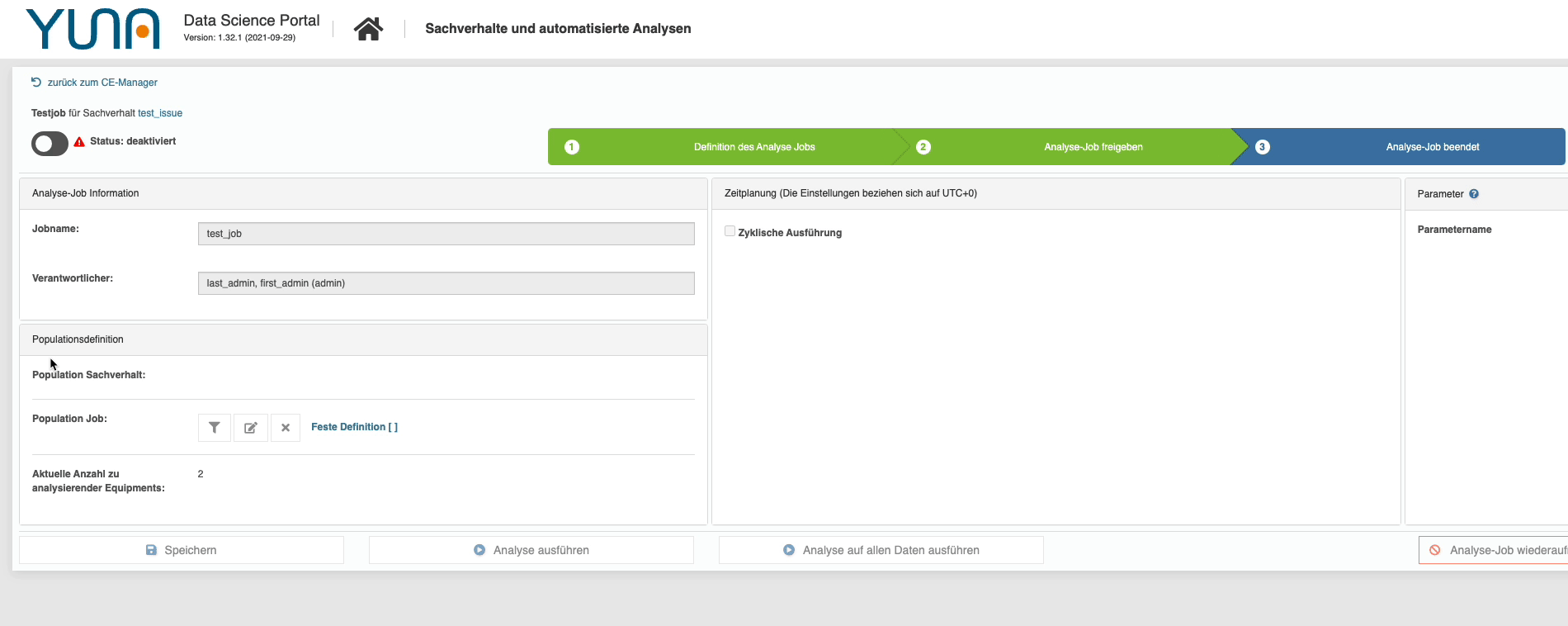
| Aus diesem Grund haben wir in der neuen Version eine Favoritenfunktionalität integriert. Ähnlich den Lesezeichen in einem Browser können nun die gewünschten Use Cases, Jobs und sogar Ansichten markiert und später schneller wiedergefunden werden. Zusätzlich lassen sich diese Favoriten natürlich auch wieder durchsuchen und sortieren – für den Fall, dass auch die Anzahl der Favoriten überhand nimmt.
Aber wir gehen noch einen Schritt weiter: Es lassen sich beliebige Daten abspeichern, ganze (gefilterte) Tabellen und die Favoriten lassen sich ebenfalls in vorhandene Tabellen nutzen. |
 |
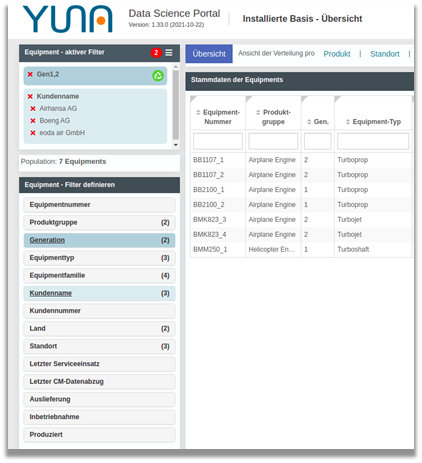
Usability: (Aktive) Einstellungen deutlich machen!
Wenn Zellen in Excel auf eine bestimmte Weise gefiltert werden, wird dies oft nur mit kleinen Symbolen angezeigt – ähnlich sieht es bei gängigen Business Intelligence und Analytik-Tools aus: Aktive Einstellungen, z.B. von Filtern, werden für den Nutzer oft nur sehr sparsam und wenig transparent visualisiert.
| Mit der neuen Version haben wir aktive Filter-Einstellungen nun farblich hervorgehoben: Dies zeigt noch deutlicher, ob überhaupt entsprechende Einstellungen ausgewählt wurden und welche Kategorien dafür verantwortlich sind, dass die Zahl der Auswahlmöglichkeiten anderen Filterkategorien eingegrenzt wird. Dabei wird farblich zwischen geladenen, also bereits definierten Filtern und vom Nutzer zusätzlich vorgenommenen Filterauswahlen unterschieden.
Das Ergebnis: User sehen nun direkt wo welche Einstellungen aktiv sind – dadurch, dass sich ganze Ansichten in YUNA teilen lassen, können die verschiedenen User nun noch schneller nachvollziehen was genau sie gerade sehen! |
 |
Numerische Tabellenspalten – Update
Numerische Tabellenspalten werden für viele verschiedene Daten gebraucht: Finanzielle Werte in unterschiedlichen Währungen, Größenverhältnisse in Prozent etc. Zudem werden je nach Sprache oder Region unterschiedliche Zahlenformate oder Zifferngruppierungen benötigt.
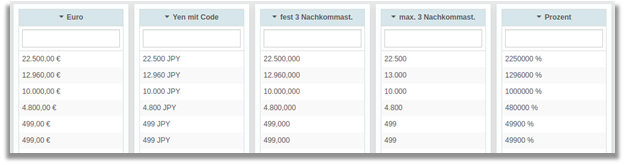
Mit der Version 1.33 haben wir die Formatierung numerischer Tabellenspalten komplett überarbeitet. So lassen sich Zahlenwerte nun umfangreich Konfigurieren, um Daten kontextbezogen darstellen und verschiedene Sprachen noch besser unterstützen zu können.
1.32
Einfacheres Kopieren von Rohdaten aus Tabellenspalten
| User-Feedback ist wichtig, wenn es um die Usability von Anwendungen geht – hier ist YUNA nicht anders. Aus diesem Feedback ist eine neue Funktion entstanden: Anstatt Tabelleninhalte zu exportieren und von dort aus zu kopieren und an anderer Stelle weiterzuverwenden, kann dies nun per Klick auf das Kopier-Icon geschehen. Dadurch wird der gesamte Inhalt der Spalte in die Zwischenablage gespeichert. Je nach Konfiguration des Dashboards werden dabei alle oder aber nur einzigartige Werte kopiert. Aktiven Filter im Tabellenwidget sowie die gewählte Sortierung werden auch zudem ebenfalls übernommen. |
 |
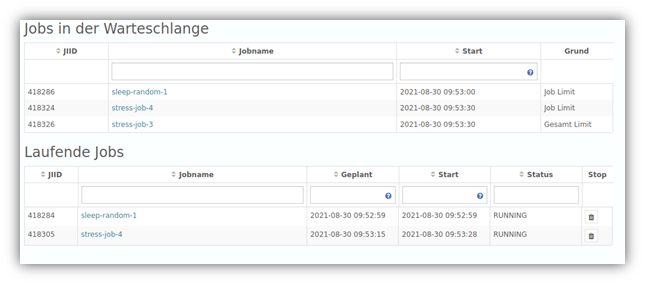
Besseres Verwalten von Analysejobs
| Unternehmen, die intensiv mit großen Datenmengen arbeiten und diese analysieren, wissen, dass Analysen so rechenintensiv werden können, dass die eingesetzte Hardware schnell an ihre Grenzen stößt und im schlimmsten Fall einen Systemzusammenbruch zur Folge haben. In Version 1.32 haben wir das Jobmanagement weiter angepasst: Wenn die definierte Anzahl der laufenden Jobs ODER die der laufenden Instanzen pro Job (also der parallelen YUNA-Instanzen) überschritten wird, landen neu hinzukommende Jobs fortan in einer Warteschlange und werden ausgeführt, sobald wieder ausreichend Kapazitäten zur Verfügung stehen. Das entsprechende Widget wurde überarbeitet und stellt die entsprechenden Warteschlangeninformationen nun im Detail dar, wodurch der Prozess für den User transparent dargestellt wird und dieser auch nachvollziehen kann, warum bestimmte Jobs noch nicht ausgeführt wurden. |
 |
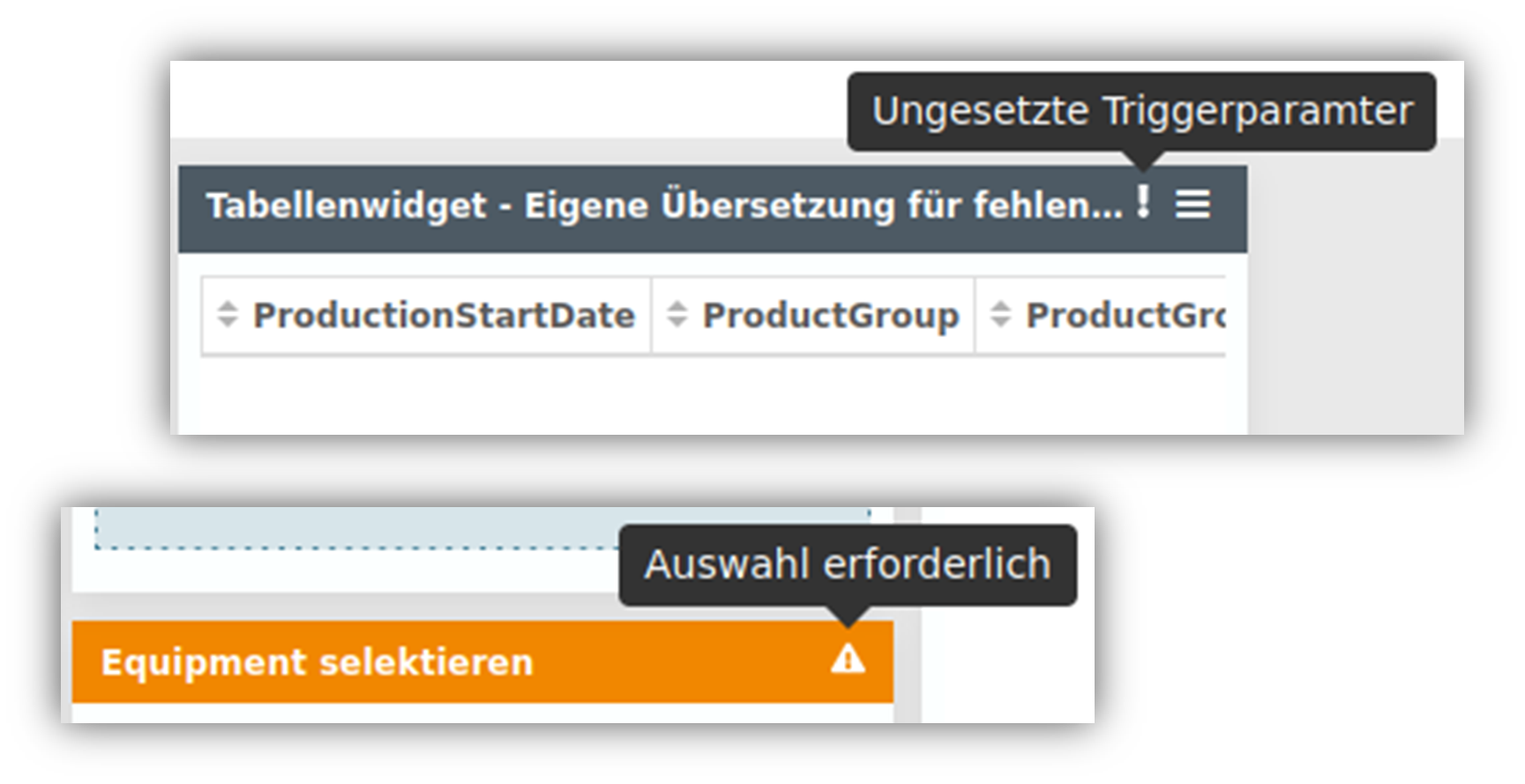
Hinweis auf fehlende Auswahl in Widgets
| Bei der Darstellung von Informationen sind Flexibilität und das Aufzeigen von Zusammenhängen entscheidende Faktoren. Dementsprechend können Widgets in YUNA aufeinander reagieren und der Input des einen verändert beispielsweise die Darstellung in einem weiteren. Hierbei kann es jedoch vorkommen, dass ein User übersieht, an welcher Stelle eine Auswahl von ihm getätigt werden muss, um an einer anderen Stellen Daten angezeigt zu bekommen. Für diese Problem gibt es nun jedoch eine Lösung: Widgets, die eine Eingabe durch den User erfordern, werden nun in YUNA zusätzlich farblich gekennzeichnet bis eine entsprechend Auswahl an Einträgen getätigt wurde. Auf der anderen Seite, also in dem Widget, in dem beispielsweise eine Darstellung erfolgen soll, wird zudem ein Hinweis eingeblendet, dass für das Anzeigen zunächst an anderer Stelle eine Auswahl von Daten getroffen werden muss. Die entsprechenden Hinweise können natürlich individuell für jedes Widget angepasst werden, falls auf unterschiedlichen Dashboards verschiedene Hinweistexte erscheinen sollen. |
 |
1.31
Usability Update für Filter
Bei Kategorien Filter, lassen sich nun per Tastendruck der gesamte Bereich zwischen zwei verschiedenen Werten auswählen.
1.30
Datenanalysen schneller umsetzen
Ein Skript allein macht noch keinen wirtschaftlichen Erfolg aus – es gibt verschiedene Faktoren, die beachtet werden müssen – organisatorisch wie auch technisch und diese multiplizieren sich mit der Anzahl der Skripte bzw. der durchzuführenden Analysen.
Mit der neuen Version haben wir verschiedene Schritte eingespart, damit Analysen schneller produktiv gesetzt werden können.
So werden beispielsweise Änderungen beim Erstellen eines Analyseauftrags direkt übernommen und müssen nicht mehr bestätigt werden. Auch ist es nicht mehr zwingend erforderlich bei einem Wechsel zwischen den einzelnen Schritten des Workflows einen Kommentar zu hinterlassen. Diese Möglichkeit wurde jedoch nicht gänzlich eliminiert, sondern wird durch einen zusätzlichen Button als optionale Funktion angeboten. Um die Nachverfolgung zu garantieren, werden weiterhin alle Prozessschritte geloggt.
War es in Produktivumgebungen bisher wichtig, jeden Schritt zu bestätigen, ist es nun möglich die Freigabe (und damit die eigentliche Ausführung) mit nur einem Klick umzusetzen. Dadurch können erfahrene Nutzer mit wesentlich weniger Klicks ans Ziel gelangen und den Jobmanager in nur drei Schritten zu durchlaufen.
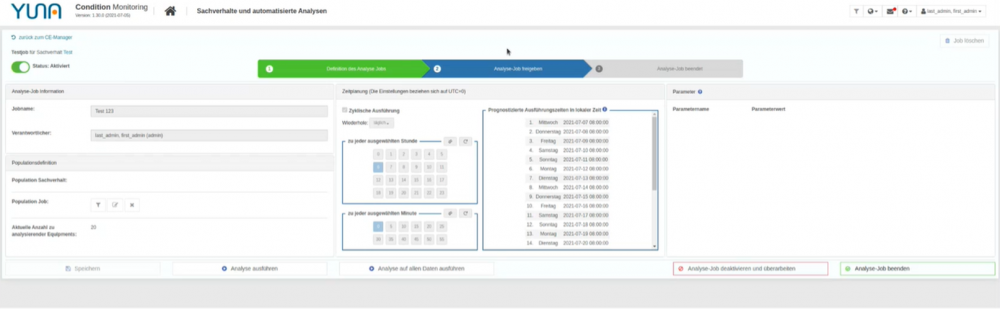
Weitere Usability-Features
| Neu hinzugekommen ist ein Suchfeld innerhalb der angezeigten Tabellen. Im Ergebnis vereinfacht das die Anwendung, indem die Suchfunktion dauerhaft erreichbar ist und nicht mehr über ein Kontextmenü aufgerufen werden muss.
Des Weiteren haben wir die Nutzung der gespeicherten Filter-Sets erweitert. Wird ein gespeicherter Filter geladen, um die angezeigten Ergebnisse einzugrenzen, lassen sich in dem Filter definierte und damit gesperrte Filterkriterien noch schneller auflösen, um Anpassungen vorzunehmen. Der Nutzer wird durch einen Tool-Tip auf diese neue Option hingewiesen, wenn er mit seinem Mauszeiger über ein ausgegrautes Filterkriterium hovert. Möchte man z.B. zur Erstellung eines neuen Filter-Sets, die im geladenen Filter definierten Kategorien nutzen, lässt sich dieser per Doppelklick „entsperren“, sodass sich einfach neue Filtersets erstellen lassen. Das Ergebnis: Bei umfassenden Analysen lassen sich mit vordefinierten Filtern für die Fachanwender zugeschnittene Darstellungen vorbereiten und dennoch durch die Anwender nach ihren Vorstellungen und Anforderungen selbst modifizieren. |
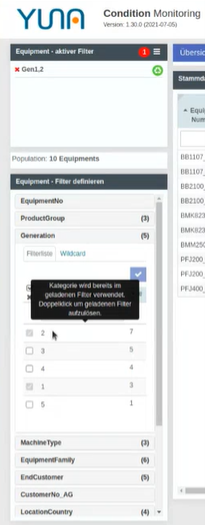 |
Dashboarding Revamped
Eines der Kernfeatures von YUNA ist die individuelle Dashboard-Erstellung. YUNA liefert keine starren Oberflächen aus, sondern bietet Nutzern die Möglichkeit diese an die eigenen Anforderungen anzupassen – sowohl optisch als auch funktional. Anders als bei anderen Lösungen besitzen die Elemente in YUNA-Dashboards auch explorative und nicht nur darstellende Funktionen.
Außerdem orientieren sich die Dashboard-Elemente am Rechte-Rollenkonzept. Ein einziges Dashboard kann also je nach Nutzergruppe eine andere Darstellungsform annehmen – genau auf die jeweiligen Bedürfnisse zugeschnitten und ohne für jede Gruppe eigene oder gar exklusive Dashboards einrichten zu müssen.
Für die vollumfängliche Individualisierung nutzt YUNA eine abgewandelte DSL (Domänenspezifische Sprache) namens „YUNA Lang“, die für die Erstellung von Dashboards optimiert ist und zahllose Komfortfunktionen bietet. Mit ihr lassen sich Dashboards zum einen schnell und mit geringem Aufwand erstellen und andererseits pixelgenau definieren. Eine maßgeschneiderte Oberfläche fast so schnell wie von der Stange.
Mit 1.30 löst YUNA Lang die bisher verwendete YUNAML ab. Damit wird das Erstellen von Dashboards noch einfacher. Auf Wunsch lassen sich die einzelnen Komponenten per Code konfigurieren und dann auf den entsprechenden YUNA-Instanzen ausrollen – anschließend übernimmt das Rechte-Rollenmanagement das Anzeigen der Dashboard-Komponenten.
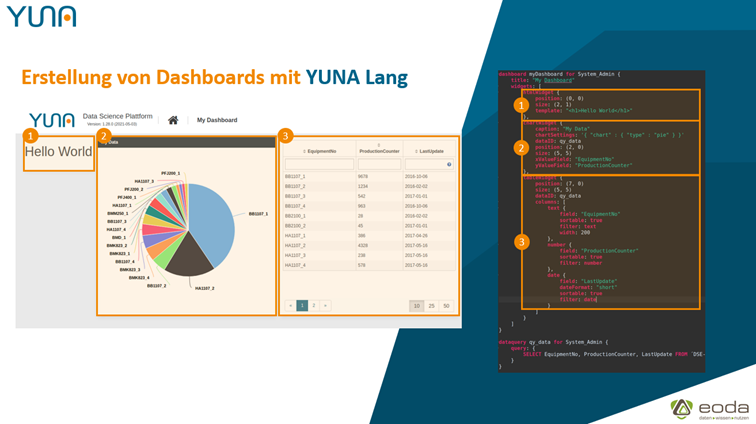
1.29
Result Rating: KI-Modelle kontinuierlich verbessern
Der Kern eines jeden KI-Systems ist ein Modell. Damit dieses dauerhaft die gewünschten Ergebnisse (wie beispielweise zuverlässige Prognosen) erzielen kann, muss es nicht nur im Vorfeld mit aufbereiteten Daten gefüttert, sondern fortlaufend mit Feedback zu den ausgegebenen Ergebnissen versorgt werden. Genau hier kommt das Result Rating ins Spiel. Der Fachexperte kann nun überall dort, wo Analyseergebnisse dargestellt werden, diese auch hinsichtlich Plausibilität bewerten. Alles, was es dafür braucht, um das Modell kontinuierlich optimieren zu können, ist also eine simple „Wahr“- oder „Falsch“-Bewertung der einzelnen Ergebnisse.
Um die Intuitivität und den Komfort dieser Funktion weiter zu verbessern, wurden nun die Voraussetzungen geschaffen, das Result-Rating-Widget mit anderen Widgets wie einem Tabellen- oder Chart-Widget zu koppeln. Dadurch müssen fortan die jeweiligen Tabelleneinträge, Graphen und Bewertungen nicht mehr separat ausgewählt werden, wodurch die benötigte Klickzahl für die Navigation deutlich reduziert wurde. Darüber hinaus übertragen sich sogar Filtereinstellungen und Sortierungen auf die zur Auswahl stehenden Bewertungsmöglichkeiten, sodass kein händischer Abgleich der Ergebnisse zu den zugehörigen Bewertungen anhand einer Nummerierung mehr nötig ist.
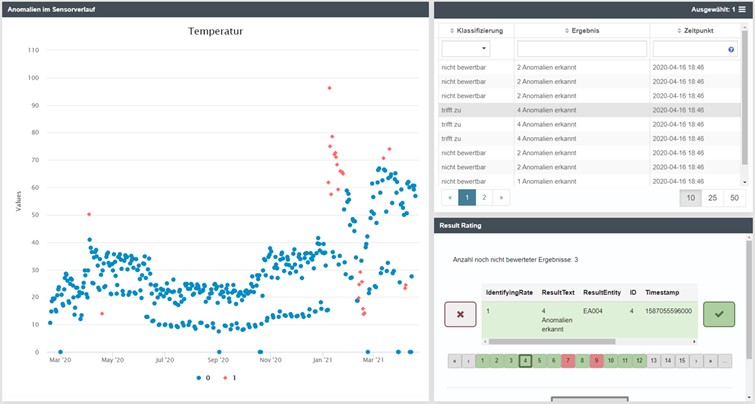
1.28
Filterpresets – Relevantes von Beginn an
YUNA-Filter orientieren sich genau wie die Dashboard-Elemente am Rechte-/Rollenkonzept. Das heißt, dass sich Dashboards zielgenau so einrichten lassen, dass die Anwender genau das sehen, was für sie relevant ist.
Die Filter lassen sich dabei auch speichern und mit anderen Nutzern und Teams teilen, müssen also nicht jedes Mal vom neuem konfiguriert werden. Die gewonnene Zeit kann dann für weiterführende Analysen oder Entwicklung neuer Fragestellungen genutzt werden.
In YUNA wird zwischen zwei Filtersystemen unterschiedenen – den klassischen Filtern und den Vorfiltern. Klassische Filter funktionieren, wie man sie von überall her kennt: Sie werden in den Dashboards auf den jeweiligen Datensatz angewendet.
[lyte id=’Gs0L1AjPnec‘ /]
Vorfilter sind eine Art Filter-Preset – sie lassen sich im Vorfeld konfigurieren und sind dabei bestimmten Gruppen zugeordnet. Auf diese Weise wird der Datenbestand bereits zu Beginn auf eine bestimmte Art, bspw. auf bestimmte Maschinenmodelle oder Sales-Kanäle eingegrenzt. Neu hinzugekommen ist die Möglichkeit, dass nun mehrere Filter über einer ODER-Verknüpfung zu einem Vorfilter zusammengeschlossen werden.
Per REST-API lassen sich nun auch Vorfilter Anlegen und aktualisieren.
Schnelles beheben von Fehlern – Update des Server-Logs
Mit der DataID lassen sich nicht nur einzelne Objekte und ganze Abfragen aus der Datenbank referenzieren – damit lassen sich Dashboards schneller erstellen und die YUNA-Features noch einfacher nutzen.
In der neuen Version haben wir an der Stellschraube des Server-Logs gedreht: Nun erhalten Anwender in den Log detaillierte Informationen darüber wenn eine DataID nicht existiert oder Fehlerhaft ist:
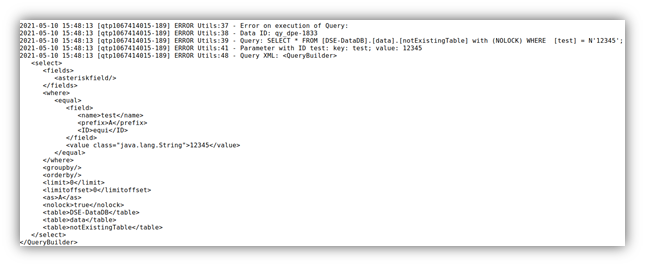 |
 |
1.27
Tabellen Export – neue Features!
| YUNA bietet viele Funktionen, den Anwendern die Arbeit miteinander zu vereinfachen. Ansichten und Filter sowie ganze Dashboards können per Link mit anderen geteilt werden – so dass die Anwender direkt die Informationen von Kolleg:innen übernehmen können. Auch per API kann YUNA diese Informationen direkt in andere Anwendungen einfließen lassen.
Trotzdem muss man gelegentlich Tabellen exportieren, um deren Daten in anderen Anwendungen nutzen zu können. Mit der neuen Version haben wir den Export stark vereinfacht sowie übersichtlicher und eindeutiger gestaltet. Die UX wurde wieder einmal verbessert, sodass man mit wesentlich weniger Klicks zum Ziel kommt. Dateinamen lassen sich nun automatisch und ganz individuell generieren – Datum, Spalteninhalten, Präfix und Co lassen sich mit minimalem Aufwand bei der Benennung miteinbeziehen. Wie bei YUNA gewohnt, können die gewählten Konfigurationen gespeichert und mit Anderen geteilt werden. |
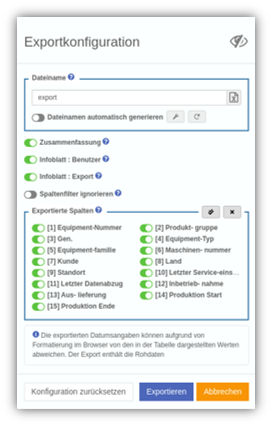 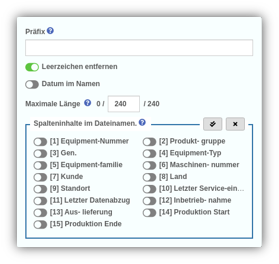 |
Wo ist was? Die Dashboard-Übersicht
| Dass Nutzer eigene Dashboards in YUNA anlegen können, ist eines der Grundprinzipien von YUNA – damit man trotzdem dem Überblick behält, haben wir ein neues Widget geschaffen: Die Dashboard-Übersicht. Hier können die einzelnen Anwender alle verfügbaren Dashboards unter dem aktuellen Referenz-Tag einsehen.
Die Referenz-Tags – vereinfacht gesagt Sammlungen von zusammengehörigen Dashboards und ermöglicht das ermöglichen das unkomplizierte Wechseln zwischen einzelnen Dashboards z.B. zwischen verschiedenen Use Cases |
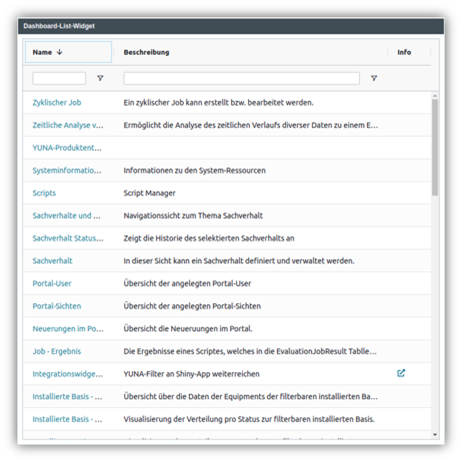 |
Der Wunsch nach Vergessen – oder Erinnern: „Angemeldet bleiben“
Damit Anwender sich nicht jedes Mal neu einloggen müssen, gibt es RememberMe-Cookies. Oft sind diese Cookies ständig aktiv oder deaktivieren sich nach einer Session.

Dieser Zeitraum kann in YUNA nun individuell konfiguriert werden – standardmäßig sind 30 Tage gesetzt. So kann beispielsweise identifiziert werden, ob ein Nutzer noch aktiv ist.
1.26
YUNA wird noch sicherer
Der funktionale Kern von YUNA, unsere CORE-API, wurde noch weiter gehärtet. Ab sofort haben alle Rollen, mit Ausnahme der System-Admins, eine reine Leseberechtigung. So lassen sich gleichzeitig alle Prozesse weiterhin einsehen, sind aber vor Änderungen gesichert.
Die CORE-API steuert alle zentralen Vorgänge in YUNA. Mit ihr lassen sich die einzelnen Module wie Nutzerverwaltung, Analysejobs, die Eventrigger und Authentifizierungen steuern.
YUNA wird einfacher
In der neuen Version haben wir u.a. den Skriptmanager vereinfacht. Analyseskripte können nun nach den Namen gefiltert werden. Ferner werden die YUNA-Standardfilter nicht mehr aufgelöst dargestellt, was die Übersicht deutlich verschlank.
Für die Funktion der „GenLinks“ gibt es nun eine dedizierte Option, ob diese Links in einem neuen Tab oder dem aktuellen Fenster geöffnet werden sollen.
Data Scientists und Anwender rücken noch näher zusammen
Die Weichen für die neue Messenger-Funktion sind gestellt. Mit ihr lassen sich nicht nur Systemnachrichten empfangen, die Anwender können sich auch innerhalb von YUNA direkt Informationen als Nachricht zukommen lassen. Dadurch entfällt das Wechseln auf Drittanwendungen, um sich auszutauschen und/oder Informationen weiterzugeben.
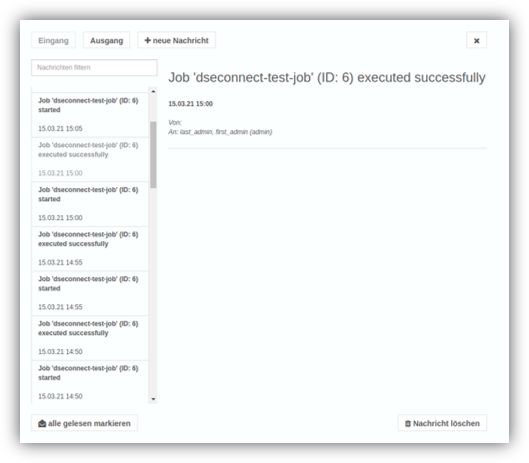
In der aktuellen Version ist die Schnittstelle bereits implementiert und lässt sich in der Konfigurationsdatei aktivieren.
1.25
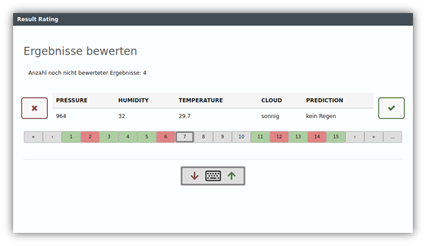
Modelle trainieren im Vorbeigehen
Trainingsdaten zu erzeugen war bis heute eine große Herausforderung. Mit YUNA geschieht dies nun im Vorbeigehen. In jedem Dashboard kann das Result Rating direkt eingebunden werden. Somit hat der Nutzer an Ort und Stelle der Ergebnispräsentation die Möglichkeit durch Bewerten der Ergebnisse Traininsdaten zu erzeugen. Ihre Ergebnisse verbessern sich deutlich durch die bessere Datengrundlage, wenn sie diese in Supervised Models wieder aufgreifen.
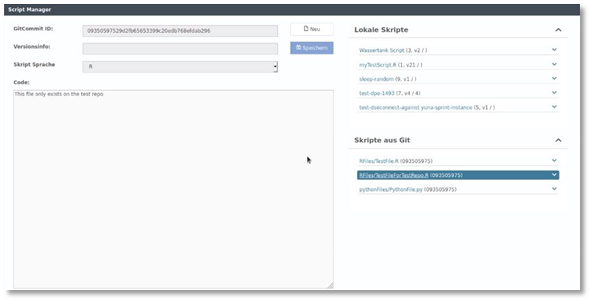
Staging und Model-Deployment über Git-Branches
Ein Automatisiertes Deployment der Analyse-Skripte wird in YUNA mit einem angebundem Git-Repository verwirklicht. Nun ist es möglich einen bestimmten Branch festzulegen. Somit können über die verschiedene Branches verschiedene Stages (Development, Test, Productive) oder auch das Deployment verschiedener Modelle auf unterschiedliche YUNA Instanzen realisiert werden.
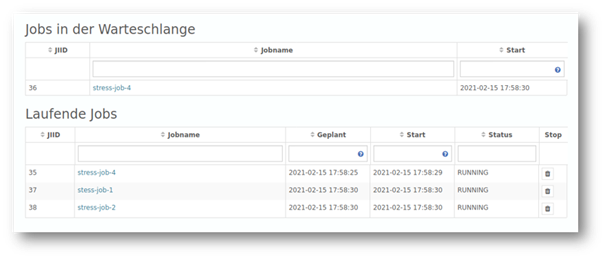
Bessere Planbarkeit: Analysen immer im Blick behalten
Was ist mit meiner Analyse geschehen, die um 11:00 Uhr starten sollten? Wieso finde ich sich nicht im Log? Diese und andere Fragen haben wir mit einer neuen Komfort-Funktion beantwortet. Bei komplexen Zusammenhängen können Analyse-Jobs z.B. durch Abhängigkeiten zu anderen Jobs zu anderen Zeiten starten als ursprünglich geplant.
In der neuen Version zeigt die System-Übersicht nun den geplanten sowie den tatsächlichen Start jedes einzelnen Analyse-Jobs, um somit die Wartung der YUNA Instanz besser planen zu können.
1.24
YUNA meets Git: Git Repo mit YUNA synchronisieren
Skripte für produktive Analyse-Jobs werden von YUNA verwaltet. Ob für ETL, Datenaufbereitung, ML-Modelle oder Visualisierungen: Anpassungen an den Skripten sowie deren Ergebnissen – zum Beispiel durch den Input von Fachanwendern oder Endnutzern – sollten durch eine gute Dokumentation jederzeit nachvollziehbar sein. Ab YUNA 1.24 ist es nun möglich, ein Git-Repository anzubinden und mit YUNA zu synchronisieren.
![]()
YUNA-Nutzer können so – je nach ihrer Berechtigungsstufe – auf das Git-Repo der Data-Scientists zugreifen und Skripte für die jeweiligen Phasen eines Workflows von Entwicklung über Test bis Produktiv deployen. Durch die Git-Integration in YUNA werden anspruchsvolle Szenarien für das Deployment von Data-Science-Skripten weniger fehleranfällig und deutlich einfacher und schneller umzusetzen.
Übersicht der wartenden Analyse-Jobs
In YUNA kann der Nutzer die Ausführung jeder Analyse in Analyse-Jobs zeitlich festlegen. Dabei steuert YUNA automatisch die Einreihung der jeweiligen Skripte in einem Zeitplan. Ab YUNA 1.24 wird der exakte Startzeitpunkt eines eingereihten Jobs dargestellt. Durch die Verbesserung der Nachvollziehbarkeit kann z.B. das Update oder ein Neustart einer YUNA-Instanz besser geplant werden, ohne dass der Durchlauf eines relevanten Analyse-Jobs dadurch abgebrochen wird.
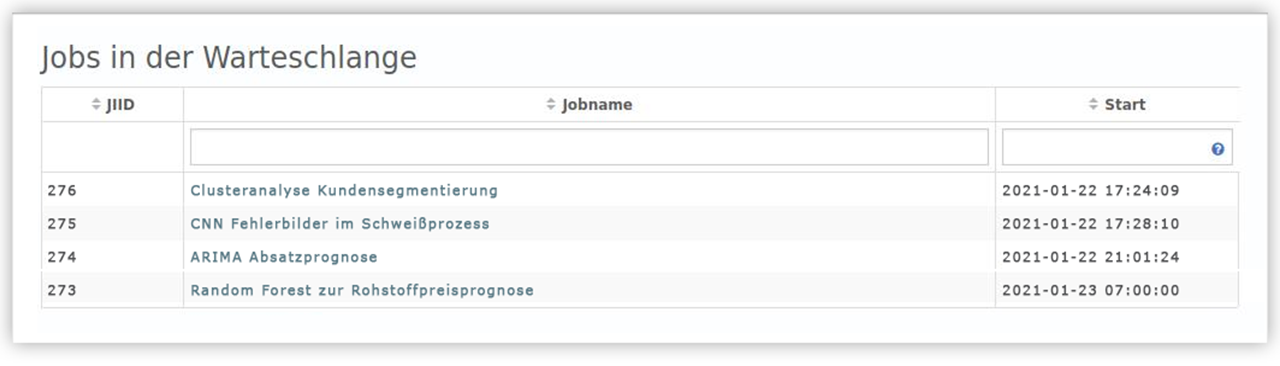
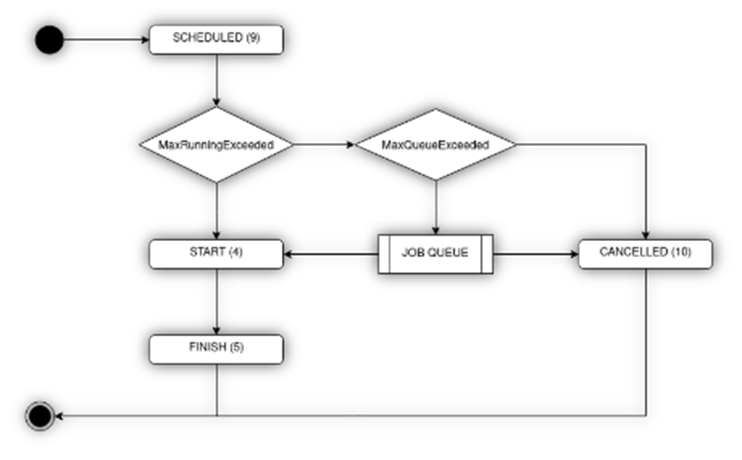
Job-Status für einfacheres DebuggingEin Analyse-Job durchläuft in seinem ggf. sich zyklisch wiederholenden Lebenszyklus verschiedene Phasen wie SCHEDULED, START, FINISHED, CANCELLED. YUNA 1.24 zeigt nun jederzeit die Phase an, in der sich ein Job befindet. Dadurch werden die Fehlersuche und das Debuggen eines Skriptes während der Entwicklung einer Analyse vereinfacht. |
 |
Automatisches Scriptlog-Cleanup
YUNA bietet in den Systemeinstellungen die Möglichkeit, optionale zyklische Routinen für das System zu definieren. Diese wurden in YUNA 1.24 um eine weitere Aktion erweitert, die es dem Administrator ermöglicht, die erzeugten Logs von Analyse-Skripten in einem definierten Zeitfenster zu bereinigen. Somit werden System-Ressourcen geschont und die Übersicht gesteigert.
Vereinfachte Dashboard-Entwicklung mit YUNA-ML
In YUNA wird ein Dashboard durch die an XML angelehnte YUNA-eigene Beschreibungssprache YUNA-ML definiert. Zur Veröffentlichung wird das jeweilige Skript geparsed, validiert und das Ergebnis schließlich geloggt. Das Logging wurde nun überarbeitet und übersichtlicher gestaltet, um das Entwickeln von Dashboards zu vereinfachen.
2020
Mehr erfahren
1.23
Automatisches Leeren von Log-Einträgen
Durchgehendes Monitoring von Analysen und trotzdem den Überblick behalten: YUNA bietet umfassendes Logging während der gesamten Datenanalysen. Damit nehmen diese Einträge keine Überhand nehmen und die Übersicht geht nicht verloren geht, kann nun ein wählbarer Zeitraum gewählt werden, nach dem Log-Einträge automatisch gelöscht werden.
Abrufen von Jobparametern einer Instanz
Wie ist meine YUNA-Instanz konfiguriert? Lassen Sie sich alle relevanten Informationen aus der Datenbank anzeigen.
Natürlich kann man die diese Informationen auch über ein das Tabellen-Widget direkt in einem YUNA-Dashboard anzeigen lassen.
„YUNA Support“ -Eintrag konfigurieren
Die Sichtbarkeit des Support-Buttons kann nun über eine entsprechende Änderung für Nicht-Administratoren konfiguriert werden.
1.21
Vereinfachte Zeitplanung von Analysen
| In diesem Release haben wir die zyklische Ausführung von Analyseskripten erheblich vereinfacht. Was hat sich konkret geändert? Die Zeitpunkte der Analysen lassen sich nun ganz intuitiv zu gewünschten Zyklen zusammenstellen. So lassen sich beispielweise auch wiederkehrende Wartungsfenster und andere Ereignisse bereits von Anfang einplanen, sodass diese nicht mehr mit wichtigen Aufgaben kollidieren | 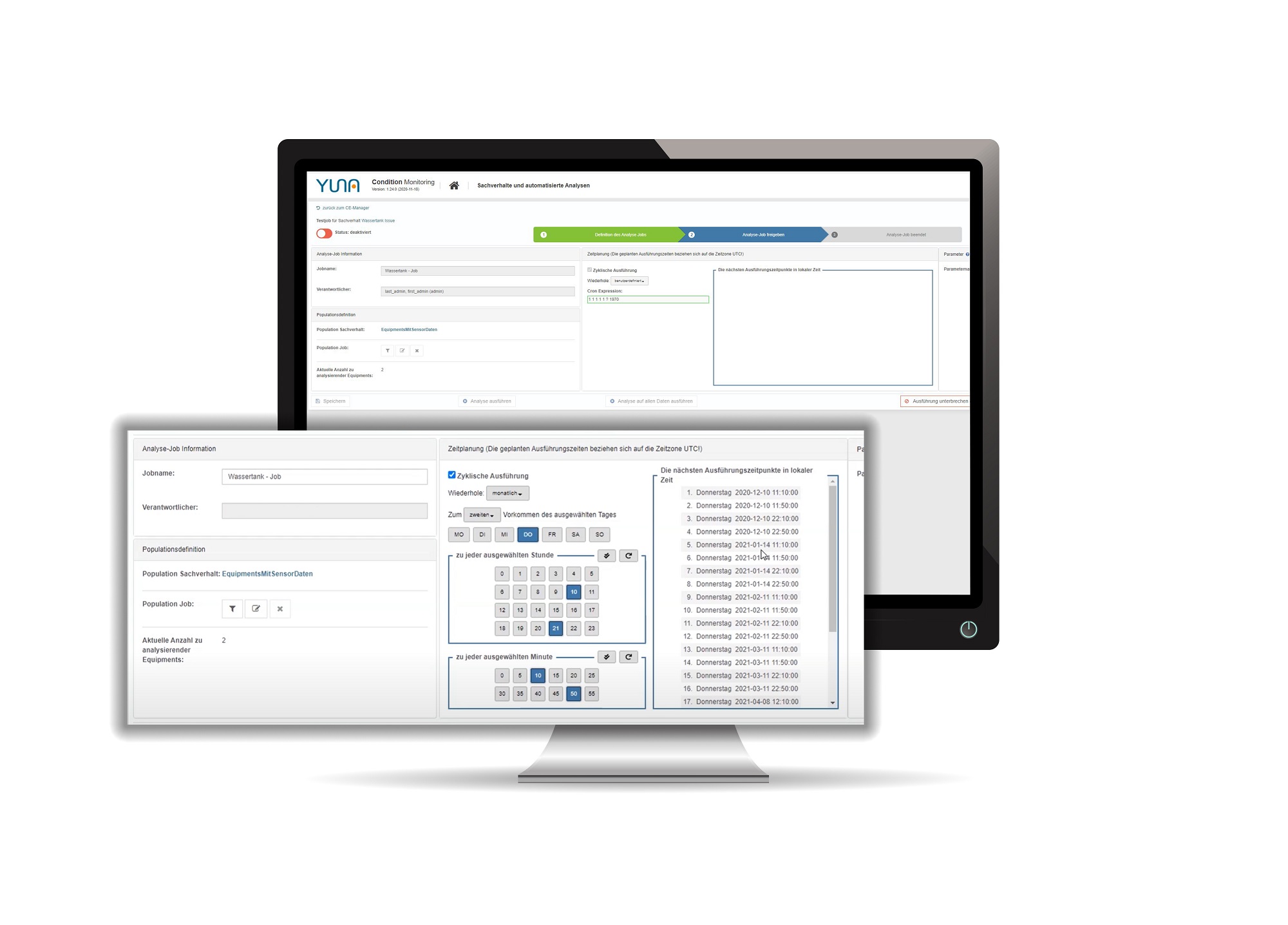 |
1.21 – „Technical Overhaul“
Ein neuer Imageviewer
Wir haben das Widget „Imageviewer“ in YUNA komplett überarbeitet. Mit dem Widget lassen sich in Datenbanken gespeicherte Bilder direkt in YUNA anzeigen. Bei den Bildern kann es sich beispielsweise um Fotografien oder automatisierte Visualisierungen von Analysen handeln. Neben der Überarbeitung des User Interface, besitzt der Imageviewer weitere hilfreiche Features.
Mehrere Wartungsfenster
Bei der Wartung, z.B. im Kontext eines Predictive Maintenance – Systems ist es nötig, dass bereits geplante Analyse-Jobs (z.B. auszuführende Analyseskripte) von der geplanten Ausführung gestoppt werden. Mit diesem Release haben wir die Möglichkeit geschaffen, die Wartungsfenster noch komfortabler zu planen. Beliebig viele Wartungsfenster können individuell über Dashboards erstellt werden. Dadurch lassen sich Wartungen (z.B. an Maschinen oder Servern) nun noch einfacher planen.
1.20a
Gruppenfilter für Teams
In diesem Sprint haben wir das Filter-System von YUNA für effektive Teamarbeit optimiert. Nach wie vor gibt es private und globale Filter, also solche, die ein User nur selbst verwendet und solche, die er mit allen anderen Nutzern teilt. Neu hinzugekommen sind Gruppenfilter, also Filter, die einem definierbarem Team gehören und von diesem nicht nur verwendet, sondern auch editiert werden können. So können auch Gruppen von Nutzern genau die Filter sehen und bearbeiten, die sie benötigen.
Übergabe der aktuellen URL-Parameter bei Links (genLink)
Um Dashboard-Entwicklern mehr Flexibilität bei der Widget-Gestaltung zu bieten, haben wir die Konfiguration von genLinks so erweitert, dass die aktuell aktiven URL-Parameter zusätzlich zu den explizit konfigurierten Parametern übergeben werden können.
Interessante Links zum Release
1.20
Damit Datenprodukte noch schneller entwickelt und eingesetzt werden können, wird YUNA stetig weiterentwickelt. In diesem Sprint haben wir die Weichen für ein neues Feature gesetzt:
- Mit der kommenden Git-Integration wird es möglich sein, Skripte direkt aus Git heraus in YUNA zu importieren. Durch diese Funktion können Data-Science-Projekte schneller und sicherer entwickelt und gestartet werden
1.19
Wir haben die Zeit genutzt, um das Tabellenwidget zu optimieren:
- Im Tabellenwidget werden, unter Verwendung der Option „addColumns„, NULL-Werte nicht mehr als NaN angezeigt. Die Option „addColumns“ dient dazu dynamisch Spalten, die im Ergebnis einer Query zurückgeliefert werden, zur Tabelle hinzuzufügen.
- Dynamisch zugefügte Spalten, die durch „addColumns“ zugefügt wurde, werden nun automatisch entfernt, sobald sich diese nicht mehr im neuen Datensatz befinden. Die Änderung betrifft Datensätze die beispw. durch ein Query entsprechend geändert wurden.
- Unter bestimmten Konfigurationen war der Export verfügbar – wurde aber nicht durchgeführt. Das Verhalten des Widgets wurde so angepasst, dass es den Erwartungen der Nutzer entspricht.
- Bei Generierung eines Charts aus einer Tabelle heraus, wurde in seltenen Fällen fälschlicherweise angezeigt, dass keine numerische Spalte für den Chart verfügbar sei. Dies wurde behoben.
1.18
Mit Version 1.18 sind neue Features hinzugekommen:
dseconnect als REST-API
dseconnect ist ein Connectivity-Paket für R, mit dem die Interaktion zwischen Skripten und YUNA hergestellt werden. Es bietet verschiedene Komfortfunktionen wie beispielsweise die Nutzung von DataIDs und Filtern. Wir haben das Paket erweitert, so dass nun auch beliebige REST-APIs von Fremdsystemen angesprochen werden können, um deren Ergebnisse in YUNA zu verwenden und darzustellen.
- Es kann sich via REST-API gegen das System authentifiziert werden
- DataIDs können via REST abgefragt werden und deren Ergebnisse gespeichert werden
- Via REST-API kann auf Filter zugegriffen werden
Der weiterführende Link zur dseconnect-API-Dokumentation finden Sie hier!
Globales deaktivieren automatischer Analyse-Jobs
Automatische Analyse-Jobs können nun global deaktiviert werden. Dadurch kann im Fehlerfall die Ursachensuche deutlich erleichtert werden.
- Im Systeminfo-Widget (de-)aktivierbar
- Zeitgesteuerte Jobs werden nicht mehr gestartet
- Manuelle Jobs werden weiterhin gestartet
- Bereits laufende Jobs werden nicht abgebrochen
Sowie kleinere Änderungen und Bugfixes.
1.17
Mit Version 1.17 sind neue Features hinzugekommen:
Escaping in genLinks
\“) bewirkt werden.Entfernen von YUNAML-Inhalten unter Referenz-Tags
Dashboards in YUNA werden während der Entwicklung häufig unter einem Referenz-Tag deployed, um die Sichtbarkeit für bestimmte Nutzergruppen einzuschränken. Wir haben einen Mechanismus eingebaut, um diese Inhalte aus der Datenbank zu entfernen, sobald diese z.B. veröffentlicht wurde und daher nicht mehr benötigt wird.
Parameter zur autom. Anmeldung an Zielservern bei CORS-Requests
Der HTTP-Provider ermöglicht es HTTP-Schnittstellen in YUNA-Dashboards zu integrieren und somit Daten von externen Services in Dashboards einzubinden oder umgekehrt die Daten aus einem Dashboard an diese zu senden. Der Parameter ‚unsafeCredentialDelegation‘ des HTTP-Providers erlaubt es die automatische Anmeldung an Zielservern bei CORS-Requests zu aktivieren.Standardmäßig verbietet eine Browserrichtlinie die automatische Anmeldung bei einem CORS-Request.
Sowie kleinere Änderungen und Bugfixes.
1.16
Unterschiedliche Datenbankzugriffe aus verschiedenen Sachverhaltstypen
Je Sachverhalt kann die zu verwendende DataSource ausgewählt werden, um die Datenbankanfragen restringieren zu können.
Verschlüsselte Connections auf Daten-DBs
Alle Client-Verbindungen aus dem YUNA-Produktumfeld können so konfiguriert werden, dass sie nur noch über verschlüsselte Verbindungen erfolgen.
JQuery im HTML-Widget
Es ist möglich, JQuery im HTML-Widget einzubinden.
2019
Mehr erfahren
Dezember 2019 – 1.14
HTTP-Provider
Neue YUNAML-Komponente, die die Einbindung von externen HTTP-APIs in Dashboards ermöglichen.
Erweitertes Logging
Die Ausgabe von bestimmten Returnwerten aus Funktionsaufrufen im Skriptlog wird nicht mehr unterdrückt
November 2019 – 1.13
Shiny-Widget-Authentifizierung in YUNA
Mithilfe des iFrame-Widgets ist jetzt möglich, Shiny Apps einzubinden. Genauer gesagt, ist es Shiny-Apps jetzt möglich auf Daten, die in YUNA vorliegen, zuzugreifen und diese zu nutzen. Die Authentififizierung über YUNA ermöglicht es so, mit den Rollen- und Rechten den Zugriff der Shiny-App zu konfigurieren.
Result Rating: Bewerten von Analyseergebnissen per Tastendruck
Mit dem Result Rating ist im letzten Sprint ein wichtiges und komfortables Werkzeug entstanden, welches das Analysieren bzw. die Ergebnisse in noch kürzerer Zeit verbessert. In dem Moment, in dem Analyseskripte ihre ersten Ergebnisse liefern, können diese über das Result Rating noch schneller bewertet und auf Richtigkeit überprüft werden. Die Ergebnisse daraus, werden dann dem Skript zurückgespielt, sodass Data Scientists ihre Skripte entsprechend anpassen können. Dieses Feature verkürzt die bisherige branchenübliche Vorgehensweise enorm.
In der neuen Version wurde die Nutzung noch entscheidend verbessert: Das Bewerten der Ergebnisse kann nun bequem und noch schneller per Tastatureingabe erfolgen. Die Belegung der Tasten ist dabei frei wählbar und kann von jedem Nutzer entsprechend der Vorlieben eingestellt werden.
Formular-Widget: Daten können an eine Stored Procedure übergeben werden
Ab jetzt ist es möglich, die Daten, die über das Formular-Widget gesendet werden, an eine Stored Procedure zu übergeben. Mit Stored Procedures können zuvor festgelegte Abläufe und mehrere Anweisungen vom Datenbank-Client aufgerufen werden. Der Dashboard-Entwickler hat somit die größtmögliche Freiheit Eingaben des Benutzers in das System zurück zu spielen, um diese z.B. in weiteren Analysen nutzen zu können.
Lokalisierung erweitert
Es ist jetzt möglich, den Inhalt von CDATA-Blöcken, Popups, allen Tooltipps und Items im Filter-Widget zu übersetzen. CDATA-Blöcke verhindern, dass der Parser Sonderzeichen wie „<“ interpretiert.
Unsere Lokalisierung löst diesen Block auf und ermöglicht die Übersetzung dessen Inhalts.
Sonderzeichen in gesourcten Objekten
Die Verwendung von Sonderzeichen in den Namen von Parametern im HTML-Widget führte im Skriptmodus zu Fehlern. Nun können auch Sonderzeichen, wie z.B. „_“ zur Benennung von HTML Parametern im Skriptmodus genutzt werden.