Wie man Analysen verbessert – Von Unsupervised zu Supervised Learning
Das Vorbereiten von Daten für weitere Analysen ist ein wichtiger Schritt bei der Entwicklung neuer digitaler Services. Was braucht es, damit aus Daten Informationen werden, mit denen sich erfolgreiche Analysen entwickeln lassen? Was ist (un)supervised Learning und wie können Anwender auch ohne Data-Science-Hintergrund Daten labeln? Darum geht es in diesem Beitrag.
Inhalt
Eine allgemeine Einführung - Mensch vs. KI
Bei Datenanalysen geht es nicht nur um möglichst genaue Algorithmen, es geht auch darum, was mit den Ergebnissen geschehen soll – in welchem Kontext sie zu sehen sind. Wir Menschen sind gut darin das „Große Ganze“ zu sehen. Wir sind in der Lage, mit unserer Erfahrung und Expertise die Zukunft vorauszuplanen. Bei der Planung folgen wir nicht immer starren Wegen und Regeln, sondern denken auch in anderen Richtungen, wenn wir „What-if“-Szenarien vorausplanen. Was aber wichtiger ist: Menschen sind neugierig und kreativ. Wir fragen uns oft, „Warum“ etwas genau so ist, wie es ist und suchen Wege, wie wir diese Fragen beantworten können.
Im Vergleich zu Algorithmen sind wir aber auch unzuverlässige Speicher. Die wenigsten von uns können sich zu jeder Zeit an alles erinnern. Je größer die Menge an Daten und Informationen desto wahrscheinlicher ist es, dass wir etwas vergessen. Wir beziehen uns also bei der Planung auf eine unvollständige Datenbasis. Auch denken wir oft zu linear. Komplexe Zusammenhänge oder exponentielle Abhängigkeiten sind für uns im ersten Moment schwer greifbar.
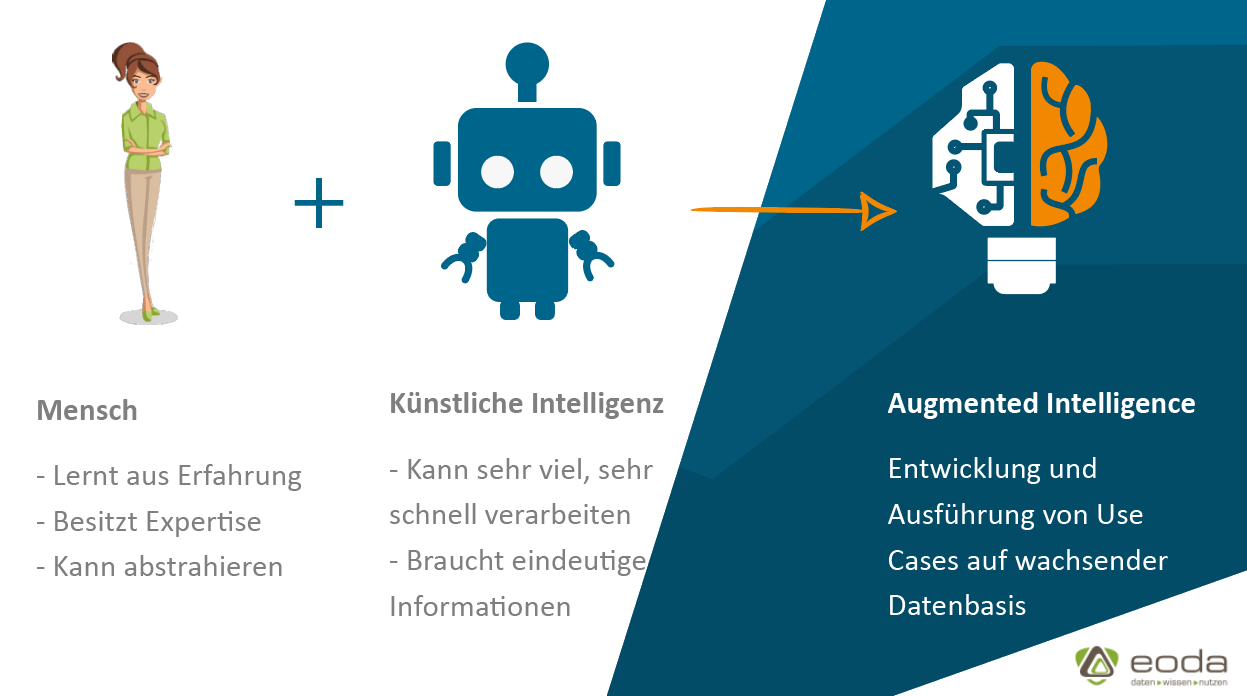
Künstliche Intelligenz auf der anderen Seite ist hier besonders gut: Algorithmen nutzen alle Informationen, die ihnen zu Verfügung stehen. Auch können Sie Daten viel schneller miteinander verknüpfen, Muster und Trends ableiten und das mit Datenmengen, die für den Menschen nicht erfassbar sind.
Von Rohdaten zur Vorhersage
| Jede gute Analyse mit einem Ziel beginnt mit der Auswahl der relevanten Daten. Maschinen besitzen oft unterschiedliche Sensoren oder lassen sich mit zusätzlichen Sensoren zur Überwachung der Qualitätssicherung und der Wartung erweitern. Andere Beispiele können Daten aus CRM-Systemen, Dokumente, Bilder, E-Mails oder Social-Media-Posts sein.
Bei diesen Daten spricht man von „ungelabelten Daten“. Damit diese für eine zielgerichtete Analyse genutzt werden können, müssen sie oft in „gelabelte Daten“ in einem Trainingsdatensatz überführt werden. Der effektivste Weg um dies zu realisieren, ist die Kombination aus menschlicher Expertise und Machine-Learning-Algorithmen. Diese zwei Seiten zusammenzubringen, ist Ansatzpunkt von verschiedenen Augmented-Intelligence-Lösungen auf dem Markt – besonders im Umfeld von Self-Service-BI bzw. Analytikplattformen. |
Unlabeled Data
Enthalten reine Werte, liefern aber Algorithmen keine weiteren Informationen und werden häufig durch „Unsupervised Learning“-Ansätze analysiert. Für die Nutzung z.B. für Vorhersagen, müssen den Daten weitere Informationen zugeordnet werden. Beispiele für ungelabelte Daten sind Fotos oder eben Sensordaten von Maschinen. Sie finden bei Unsupervised Learning Verwendung. Labeled Data
Daten, denen diese Informationen zugeordnet sind. Fotos wurden hier beispielweise mit „Haus“ oder „Fußgängerüberweg“ kategorisiert. Gelabelte Daten werden für Vorhersagen beim Supervised Learning Verwendung. |
Ein einfaches Beispiel aus der Industrie
Man nehme ein Modell zur Anomalieerkennung und wendet dieses auf die gewünschten Datenquellen (diese können vielfältig sein) an. In der ersten Iteration gibt der Algorithmus per Unsupervised Learning, gemäß den festgelegten Parametern, entsprechende Ergebnisse aus den Analysen der ungelabelten Daten aus.
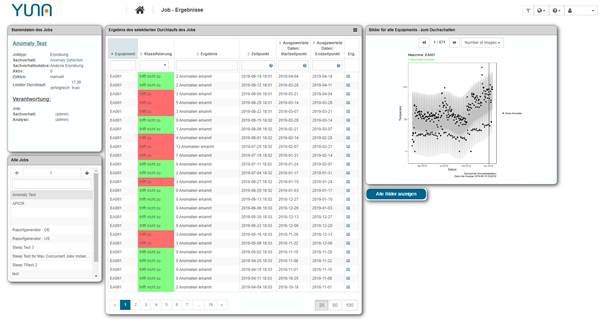
Bei Algorithmen muss jedoch ein Kompromiss zwischen Sensitivität und Spezifizität gefunden werden. Ersteres bedingt quasi einen „Schwellenwert“ der bestimmt, ab wann der Algorithmus einen Wert zu weiteren Analyse heranzieht, letzteres bedingt die Einstufung des Werts z.B. als Anomalie. Ist die Sensitivität zu gering, können nicht alle Anomalien oder Ausfälle erkannt bzw. vorhergesagt werden. Ist sie zu hoch, werden unnötige Systemressourcen darauf verwendet irrelevante Daten zu untersuchen. Ist wiederum die Spezifizität des Algorithmus ebenfalls niedrig, ergeben sich zu viele False Positive Ergebnisse.
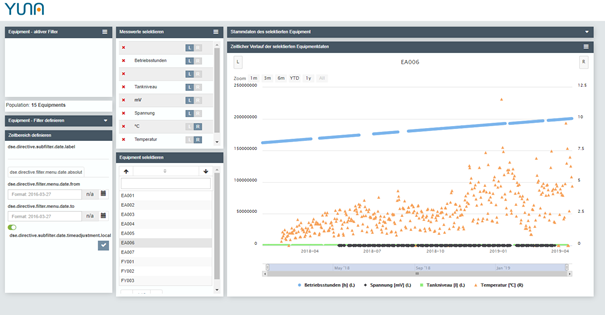
Die Antwort auf dieses Dilemma lässt sich auch hier im Ansatz von Augmented Intelligence finden. Dabei unterstützt man die menschliche Expertise mit Methoden und Technologien, beispielweise Künstlicher Intelligenz. Genau diesen Ansatz verfolgen wir mit unserer Data-Science-Plattform YUNA.
YUNA visualisiert diese Daten automatisch in einem Dashboard und stellt sie den Anwendern zur Verfügung. Zusätzlich zur Visualisierung ermöglicht YUNA das Bewerten dieser Analysergebnisse per Tastendruck. Diese können anhand ihrer Expertise die visualisierten Daten dem entsprechenden Kontext zuordnen (z.B. ob die gefunden Anomalie problematisch ist oder innerhalb der Toleranz liegen).
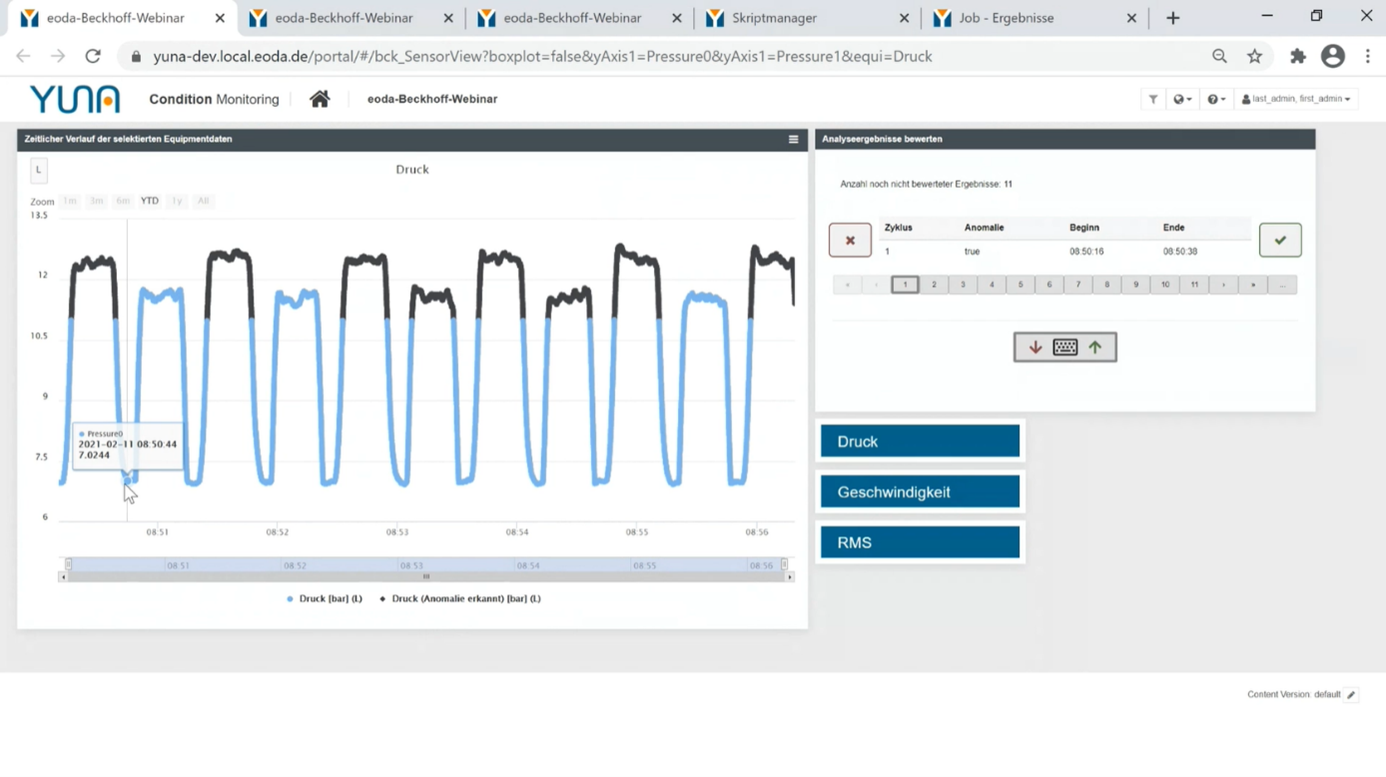
Die Bewertung wiederum dient in YUNA dazu, dass Data Scientists die entsprechenden Modelle zur Anomaliererkennung weiter spezifizieren können und die Sensitivität anpassen können.
Die nächste Iteration liefert nun genauere Ergebnisse und kann dann wieder als Basis für Active Learning genutzt werden und so sogar Edge Cases abbilden. Der optimierte Algorithmus kann aus den bewerteten Ergebnissen Zusammenhänge schließen und bei völlig neuen Zuständen die Anwender „zu Rate ziehen“. Diese bewerten die entsprechenden Fälle, der Algorithmus „lernt“ mit den neuen Gegebenheiten umzugehen und die Analyse kann automatisiert präziser ablaufen. Ab diesem Punkt ist der nächste Schritt zum selbstlernenden Algorithmus nicht mehr weit.
Das Besondere: Mit der gleichen Funktion lassen sich ebenfalls ungelabelte Daten in gelabelte Daten transformieren – diese können dann wieder als Trainingsdatensätze für Algorithmen genutzt werden. Der aufwändige Prozess des Data Labeling kann durch das Result Rating stark vereinfacht werden.
Beispielhafter Prozess in YUNA
- Fragestellung wird gestellt, Anforderungen (Datenquelle, Ergebnisdarstellung etc.) werden definiert (z.B. Workshop oder in YUNA selbst)
- Skriptentwicklung durch Data Scientists
- Analyse und Ergebnisausgabe in YUNA Dashboards
- Bewertung der Ergebnisse und Weiterleitung an Data Scientists
- Optimierung der Algorithmen
- Prozess ab 4. beginnt von Neuem (abgekürzt)
- Endergebnis: Selbstlernender Algorithmus, Zeitersparnis, neue Dienste lassen sich schneller entwickeln, schnelle Time-to-Market digitaler Services
YUNA bietet darüber hinaus Funktionen, die Anwendern ermöglicht, ohne Fachkenntnisse in Data Science, Analysen und deren Ergebnisse nicht nur zu nutzen, sondern auch eigene Fragestellung in den Data Science Kontext zu überführen. Durch die Kombination von individuellen Dashboards und der Möglichkeit jederzeit auf bestehende Analyseskripte Einfluss zu nehmen und auszuführen, stellt YUNA dabei eine Art Missing-Link zwischen klassisch reinen Analytikplattformen und Self-Service-Bi-Tools dar.
Weiterführende Inhalte zum Thema
- Was ist Augmented Analytics – Chancen für Unternehmen
- Data Labeling und Annotation Services
- Augmented Intelligence
- Data Science Design Sprint