Prediction models, machine learning algorithms and scripts for data storage: The modern data science application not only shows more and more complexity, but also puts the existing infrastructure to the test by temporary resource peaks. In this article, we will show how tools such as the RStudio Job Launcher in conjunction with a Kubernetes cluster can be used to outsource the execution of arbitrary analysis scripts to the cloud, scale them and return them to the local infrastructure.
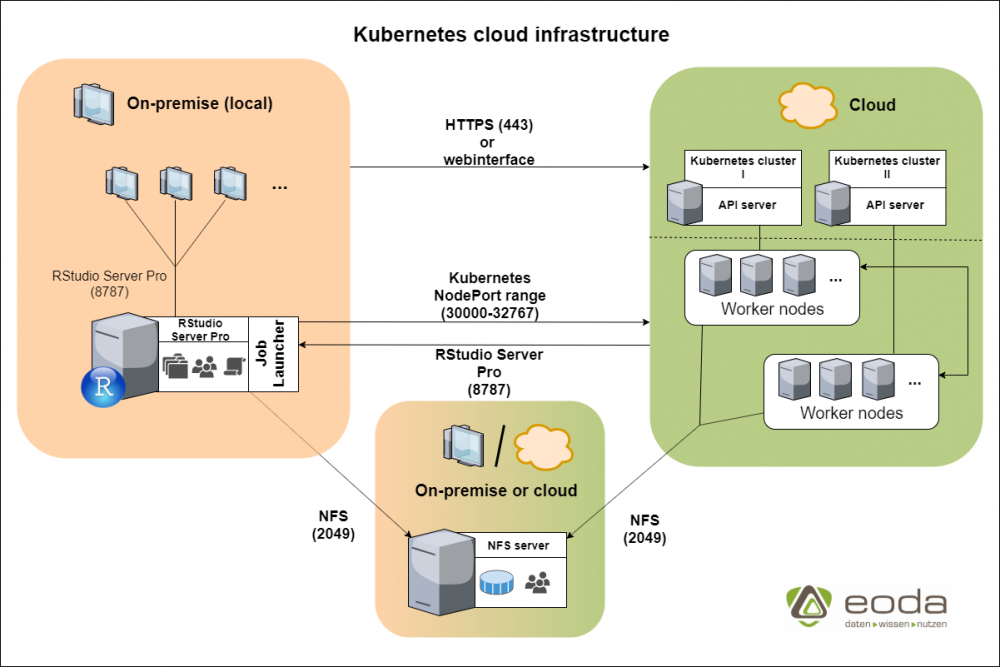
A brief introduction to Kubernetes and the Job Launcher
Kubernetes was designed by Google in 2014 and is an open source published container-orchestration system. The focus of these systems is the automated deployment, scaling and management of container applications. A Kubernetes cluster provides so-called (worker) nodes that can be addressed by other applications. Within the nodes, the necessary containers are then booted up in pods and are made available. In regard to a statistics/analysis context, the outsourcing or horizontal scalability of computation-intensive analyses is particularly interesting. Thus, in a multi-user environment, the distribution of jobs among the worker nodes ensures that the exact amount of resources required is made available, depending on the workload. In the analysis context with R, the RStudio Job Launcher, the independent tool of RStudio Server, can play to its strengths and send sessions and scripts directly to a Kubernetes cluster via plugin.
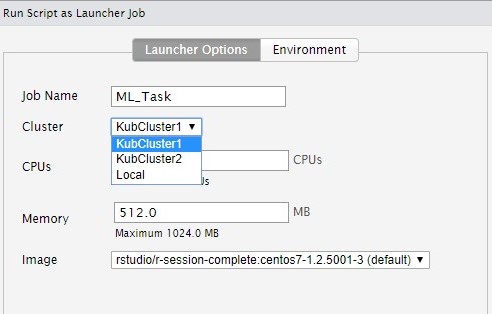
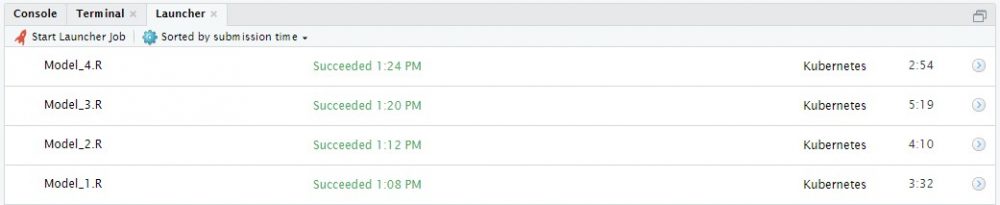
On the one hand this prevents additional costs caused by servers at-rest, on the other hand it also prevents bottlenecks, which can occur more often during workload peaks on standard systems. Based on this basic idea, the RStudio Job Launcher can also be used in local sessions by executing individual R scripts in the Kubernetes cluster and playing back their results. Data science use cases are the resource-intensive scripts, which are listed below, the simultaneous training of different analysis models or compilation tasks that can be outsourced to external nodes.
Our conclusion
Scalability, combined with on-demand provisioning and use of resources, is an ideal scenario for organizations that need to keep their data in the local data center and cannot go all the way to the cloud. In addition, by outsourcing computationally intensive processes, the local data center does not need to grow unnecessarily. This saves the purchase of additional servers in the local data center, which are only used at temporary resource peaks.
In our opinion, this scenario will be particularly interesting for companies that are not allowed to store their data in the cloud due to the constant data growth and the ever more complex requirements on the analysis infrastructure.
In addition to the advantage of processing local data hosted on-premise in a computing cluster, analyses can also base on different frameworks due to Docker images. In addition, flexible requirements on the analysis infrastructure, such as the execution of certain analyses on a GPU or CPU cluster or the booting of additional worker nodes, are easily implemented. Scaling computation-intensive processes horizontally can be achieved with little effort because access to a cluster is easier than ever, for example through Amazon’s EKS service, which provides a completely cloud-based Kubernetes cluster.
This special approach is a solution for numerous challenges for data scientists and data engineers. For this reason, we are happy to support and advise you in the planning and implementation of an IT infrastructure in your company. Learn more about aicon | analytic infrastructure consulting!